ELF 详解
ELF Header¶
注:在下面的介绍中,我们以 32 位为主进行介绍。
ELF Header 描述了 ELF 文件的概要信息,利用这个数据结构可以索引到 ELF 文件的全部信息,数据结构如下:
#define EI_NIDENT 16
typedef struct {
unsigned char e_ident[EI_NIDENT];
ELF32_Half e_type;
ELF32_Half e_machine;
ELF32_Word e_version;
ELF32_Addr e_entry;
ELF32_Off e_phoff;
ELF32_Off e_shoff;
ELF32_Word e_flags;
ELF32_Half e_ehsize;
ELF32_Half e_phentsize;
ELF32_Half e_phnum;
ELF32_Half e_shentsize;
ELF32_Half e_shnum;
ELF32_Half e_shstrndx;
} Elf32_Ehdr;
通过 readelf -h 命令来看看示例程序中的 ELF Header 内容,显示结果如下图:
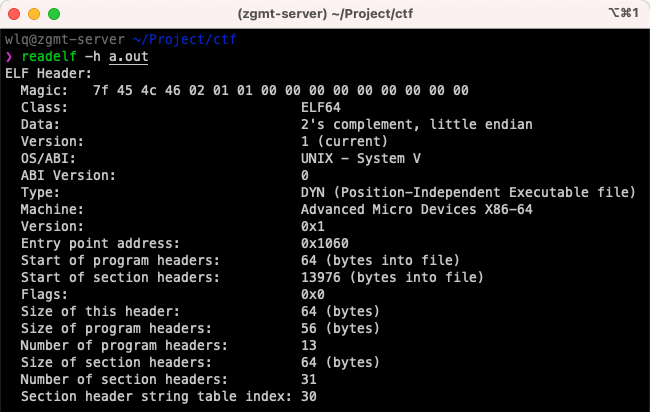
上述结构体与截图中的字段是对应的。
①e_ident
注意:图中的 Magic 字段,似乎就是 e_ident 数组的内容。
长 16 的数组,正如之前所说,ELF 提供了一个目标文件框架,以便于支持多种处理器,多种编码格式的机器。该变量给出了用于解码和解释文件中与机器无关的数据的方式。这个数组对于不同的下标的含义如下:
-
前 4 字节:魔数,正是图中的 Magic 的前四位。
-
第 5 字节:EI_CLASS,表示文件类型。ELF 文件的设计使得它可以在多种字节长度的机器之间移植,而不需要强制规定机器的最长字节长度和最短字节长度。
图中 Magic(即 e_ident)的第 5 字节为 "0x02" 表示 64 位架构文件,显示在截图中的 Class 字段中。
| EI_CLASS 名称 | 值 | 意义 |
|---|---|---|
| ELFCLASSNONE | 0 | 无效类型 |
| ELFCLASS32 | 1 | 32 位文件 |
| ELFCLASS64 | 2 | 64 位文件 |
- 第 6 字节:EI_DATA,表示目标文件中的特定处理器数据的编码方式。
图中第 6 字节为 "01" 表示小端序,显示在截图的 Data 字段中。
| EI_DATA 名称 | 值 | 意义 |
|---|---|---|
| ELFDATANONE | 0 | 无效数据编码 |
| ELFDATA2LSB | 1 | 小端 |
| ELFDATA2MSB | 2 | 大端 |
- ELFDATA2LSB 小端序:低地址存放数据低位,高地址存放数据高位(口诀:低低高高),例:
- ELFDATA2MSB 大端序:低地址存放数据高位,高地址存放数据低位,例:


-
第 7 字节:EI_VERSION,给出了 ELF 头的版本号。目前这个值必须是
EV_CURRENT,也就是此处的 "0x01"。 -
后续空字节:EI_PAD,给出了
e_ident中未使用字节的开始地址。这些字节被保留并置为 0;处理目标文件的程序应该忽略它们。如果之后这些字节被使用,EI_PAD 的值就会改变。
②e_type
标识目标文件类型:
| 名称 | 值 | 意义 |
|---|---|---|
| ET_NONE | 0 | 无文件类型 |
| ET_REL | 1 | 可重定位文件 |
| ET_EXEC | 2 | 可执行文件 |
| ET_DYN | 3 | 共享目标文件 |
| ET_CORE | 4 | 核心转储文件 |
| ET_LOPROC | 0xff00 | 处理器指定下限 |
| ET_HIPROC | 0xffff | 处理器指定上限 |
虽然核心转储文件的内容没有被详细说明,但 ET_CORE 还是被保留用于标志此类文件。从 ET_LOPROC 到 ET_HIPROC (包括边界) 被保留用于处理器指定的场景。其它值在未来必要时可被赋予新的目标文件类型。
③e_machine
指定当前文件可以运行的机器架构:
| 名称 | 值 | 意义 |
|---|---|---|
| EM_NONE | 0 | 无机器类型 |
| EM_M32 | 1 | AT&T WE 32100 |
| EM_SPARC | 2 | SPARC |
| EM_386 | 3 | Intel 80386 |
| EM_68K | 4 | Motorola 68000 |
| EM_88K | 5 | Motorola 88000 |
| EM_860 | 7 | Intel 80860 |
| EM_MIPS | 8 | MIPS RS3000 |
其中 EM 应该是 ELF Machine 的简写。
其它值被在未来必要时用于新的机器。 此外,特定处理器的 ELF 名称使用机器名称来进行区分,一般标志会有个前缀EF_ (ELF Flag)。例如,在EM_XYZ机器上名叫 WIDGET 的标志将被称为 EF_XYZ_WIDGET。
④e_version
标识目标文件的版本:
| 名称 | 值 | 意义 |
|---|---|---|
| EV_NONE | 0 | 无效版本 |
| EV_CURRENT | 1 | 当前版本 |
⑤ 其他:
| 字段 | 作用 |
|---|---|
| e_entry | 为系统转交控制权给 ELF 中相应代码的虚拟地址。如果没有相关的入口项,则这一项为 0。 |
| e_phoff | 给出程序头部表在文件中的字节偏移(Program Header table OFFset)。如果文件中没有程序头部表,则为 0。 |
| e_shoff | 给出节头表在文件中的字节偏移( Section Header table OFFset )。如果文件中没有节头表,则为 0。 |
| e_flags | 给出文件中与特定处理器相关的标志,这些标志命名格式为 EF_machine_flag。 |
| e_ehsize | 给出 ELF 文件头部的字节长度(ELF Header Size)。 |
| e_phentsize | 给出 程序头部表(Program Header Table) 中每个表项的字节长度(Program Header ENTry SIZE)。每个表项的大小相同。 |
| e_phnum | 给出 程序头部表(Program Header Table) 的项数( Program Header entry NUMber )。因此,e_phnum 与 e_phentsize 的乘积即为程序头部表的字节长度。如果文件中没有程序头部表,则该项值为 0。 |
| e_shentsize | 给出节头的字节长度(Section Header ENTry SIZE)。一个节头是节头表中的一项;节头表中所有项占据的空间大小相同。 |
| e_shnum | 给出节头表中的项数(Section Header NUMber)。因此, e_shnum 与 e_shentsize 的乘积即为节头表的字节长度。如果文件中没有节头表,则该项值为 0。 |
| e_shstrndx | 给出节头表中与节名字符串表相关的表项的索引值(Section Header table InDeX related with section name STRing table)。如果文件中没有节名字符串表,则该项值为 SHN_UNDEF。 |
Program Header Table(为执行视图的 Segment 准备)¶
Program Header Table 是一个结构体数组,其中每一个元素的类型是 Elf32_Phdr,描述了一个段(segment)或者其它系统在准备程序执行时所需要的信息,例如段的类型、起始地址等信息。
注意到,ELF Header 中的 e_phentsize 和 e_phnum 指定了该数组每个元素的大小以及元素个数。一个目标文件的段包含一个或者多个节。程序的头部只有对于可执行文件和共享目标文件有意义。
Elf32_Phdr 的数据结构如下
typedef struct {
ELF32_Word p_type; // 段的类型,或者表明了该结构的相关信息。
ELF32_Off p_offset; // 从文件开始到该段开头的第一个字节的偏移。
ELF32_Addr p_vaddr; // 该段第一个字节在内存中的虚拟地址。
ELF32_Addr p_paddr; /* 仅用于物理地址寻址相关的系统中, 由于 “System V” 忽略了应用程序的物理寻址,
可执行文件和共享目标文件的该项内容并未被限定。*/
ELF32_Word p_filesz; // 文件镜像中该段的大小,可能为 0。
ELF32_Word p_memsz; // 内存镜像中该段的大小,可能为 0。
ELF32_Word p_flags; // 与段相关的标记。
ELF32_Word p_align; /* 可加载的程序的段的 p_vaddr 以及 p_offset 的大小必须是 page 的整数倍。
该成员给出了段在文件以及内存中的对齐方式。
如果该值为 0 或 1 的话,表示不需要对齐。除此之外,p_align 应该是 2 的整数指数次方
并且 p_vaddr 与 p_offset 在模 p_align 的意义下,应该相等。*/
} Elf32_Phdr;
通过 readelf -l 命令来看看示例程序中的 Program Header Table 数组内容,可以看到该数组的每一个元素刚好是 Elf32_Phdr 结构体。
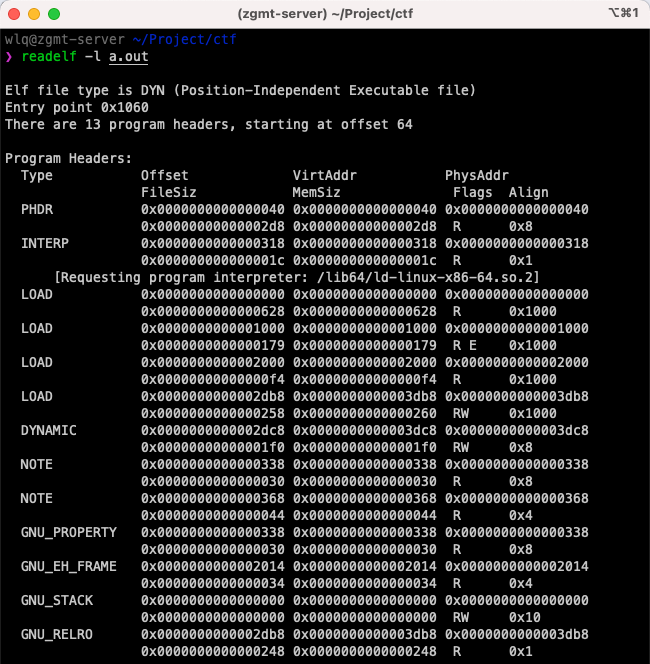
上图截取了 readelf 命令返回结果的上半部,重点解释:
- PHDR,此类型 header 元素描述了 program header table 自身的信息。从这里的内容看出:
- 示例程序的 program header table 在文件中的偏移(Offset)为 0x40,即 64 号字节处;
- 该段映射到进程空间的虚拟地址(VirtAddr)为 0x400040;PhysAddr 暂时不用,其保持和 VirtAddr 一致;
- 该段占用的文件大小 FileSiz 为 00x2d8;运行时占用进程空间内存大小 MemSiz 也为 0x2d8;
- Flags 标记表示该段的读写权限,这里”R E”表示可读可执行,说明本段属于代码段;
- Align 对齐为 8,表明本段按 8 字节对齐。
- INTERP,此类型 header 元素描述了一个特殊内存段,该段内存记录了动态加载解析器的访问路径字符串。示例程序中,该段内存位于文件偏移 0x318 处,即紧跟 program header table;映射的进程虚拟地址空间地址为 0x318;文件长度和内存映射长度均为 0x1c,即 28 个字符,具体内容为”/lib64/ld-linux-x86-64.so.2”;段属性为只读,并按字节对齐;
- LOAD,此类型 header 元素描述了可加载到进程空间的 代码段或数据段。
- DYNAMIC,此类型 header 元素描述了动态加载段,其内部通常包含了一个名为”.dynamic”的动态加载区;这也是一个数组,每个元素描述了与动态加载相关的各方面信息,我们将在动态加载中介绍。
注意:不同的段可能会有所重合,即不同的段包含相同的节。
可执行文件中的段类型如下:
| 名字 | 取值 | 说明 |
|---|---|---|
| PT_NULL | 0 | 表明段未使用,其结构中其他成员都是未定义的。 |
| PT_LOAD | 1 | 此类型段为一个可加载的段,大小由 p_filesz 和 p_memsz 描述。文件中的字节被映射到相应内存段开始处。如果 p_memsz 大于 p_filesz,“剩余” 的字节都要被置为 0。p_filesz 不能大于 p_memsz。可加载的段在程序头部中按照 p_vaddr 的升序排列。 |
| PT_DYNAMIC | 2 | 此类型段给出动态链接信息。 |
| PT_INTERP | 3 | 此类型段给出了一个以 NULL 结尾的字符串的位置和长度,该字符串将被当作解释器调用。这种段类型仅对可执行文件有意义(也可能出现在共享目标文件中)。此外,这种段在一个文件中最多出现一次。而且这种类型的段存在的话,它必须在所有可加载段项的前面。 |
| PT_NOTE | 4 | 此类型段给出附加信息的位置和大小。 |
| PT_SHLIB | 5 | 该段类型被保留,不过语义未指定。而且,包含这种类型的段的程序不符合 ABI 标准。 |
| PT_PHDR | 6 | 该段类型的数组元素如果存在的话,则给出了程序头部表自身的大小和位置,既包括在文件中也包括在内存中的信息。此类型的段在文件中最多出现一次。此外,只有程序头部表是程序的内存映像的一部分时,它才会出现。如果此类型段存在,则必须在所有可加载段项目的前面。 |
| PT_LOPROC~PT_HIPROC | 0x70000000 ~0x7fffffff | 此范围的类型保留给处理器专用语义。 |
p_flags 字段标志着段的权限,权限主要有:R(读)、W(写)、E(执行)。
例如,一般来说,.text 段一般具有读和执行权限,但是不会有写权限。数据段一般具有写,读,以及执行权限。
那么,段中的内容是什么?
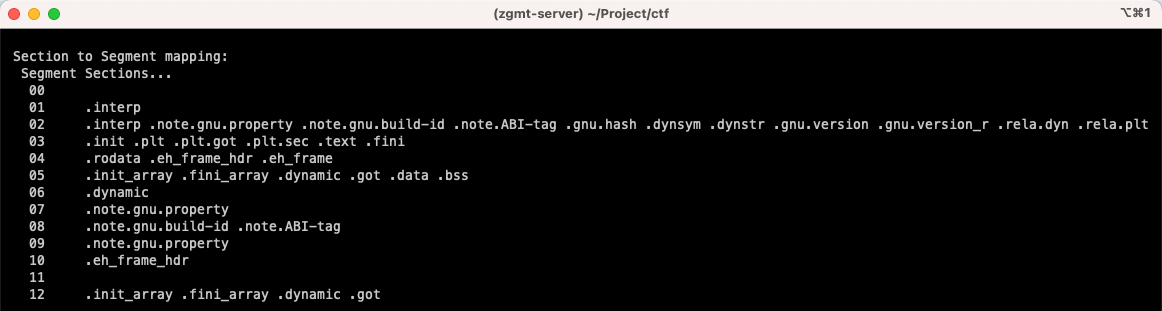
readelf 命令返回内容的下半部分给出了各段(segment)和各区(section)之间的包含关系,如下图所示。
- INTERP 段只包含了”.interp”区;
- 代码段(Text Segment) 包含”.interp”、”.plt”、”.text”等区;
- 数据段(Data Segment) 包含”.dynamic”、”.data”、”.bss”等区;
- DYNAMIC 段包含”.dynamic”区。
从这里可以看出,有些区被同时包含在多个段中。
Section Header Table(为链接视图的 Section 准备)¶
Section Header Table 通常位于文件的尾部,该结构用于定位 ELF 文件中的每个节区的具体位置。
首先,ELF 头中的 e_shoff 项给出了从文件开头到节头表位置的字节偏移。e_shnum 告诉了我们节头表包含的项数;e_shentsize 给出了每一项的字节大小。
其次,节头表是一个数组,每个数组的元素的类型是 ELF32_Shdr ,每一个元素都描述了一个节区的概要内容:
typedef struct {
ELF32_Word sh_name; /* 节名称,是节区头字符串表节区中(Section Header String Table Section)的索引,
因此该字段实际是一个数值。在字符串表中的具体内容是以 NULL 结尾的字符串。*/
ELF32_Word sh_type; // 根据节的内容和语义进行分类,具体的类型下面会介绍。
ELF32_Word sh_flags; // 每一比特代表不同的标志,描述节是否可写,可执行,需要分配内存等属性。
ELF32_Addr sh_addr; /* 如果节区将出现在进程的内存映像中,此成员给出节区的第一个字节应该在进程镜像中的位置。
否则,此字段为 0。*/
ELF32_Off sh_offset; /* 给出节区的第一个字节与文件开始处之间的偏移。
SHT_NOBITS 类型的节区不占用文件的空间,因此其 sh_offset 成员给出的是概念性的偏移。*/
ELF32_Word sh_size; /* 节区的字节大小。除非节区的类型是 SHT_NOBITS, 否则该节占用文件中的 sh_size 字节。
类型为 SHT_NOBITS 的节区长度可能非零,不过却不占用文件中的空间。*/
ELF32_Word sh_link; // 此成员给出节区头部表索引链接,其具体的解释依赖于节区类型。
ELF32_Word sh_info; // 此成员给出附加信息,其解释依赖于节区类型。
ELF32_Word sh_addralign;// 某些节区的地址需要对齐
ELF32_Word sh_entsize; /* 某些节区中存在具有固定大小的表项的表,如符号表。
对于这类节区,该成员给出每个表项的字节大小。反之,此成员取值为 0。*/
} Elf32_Shdr;
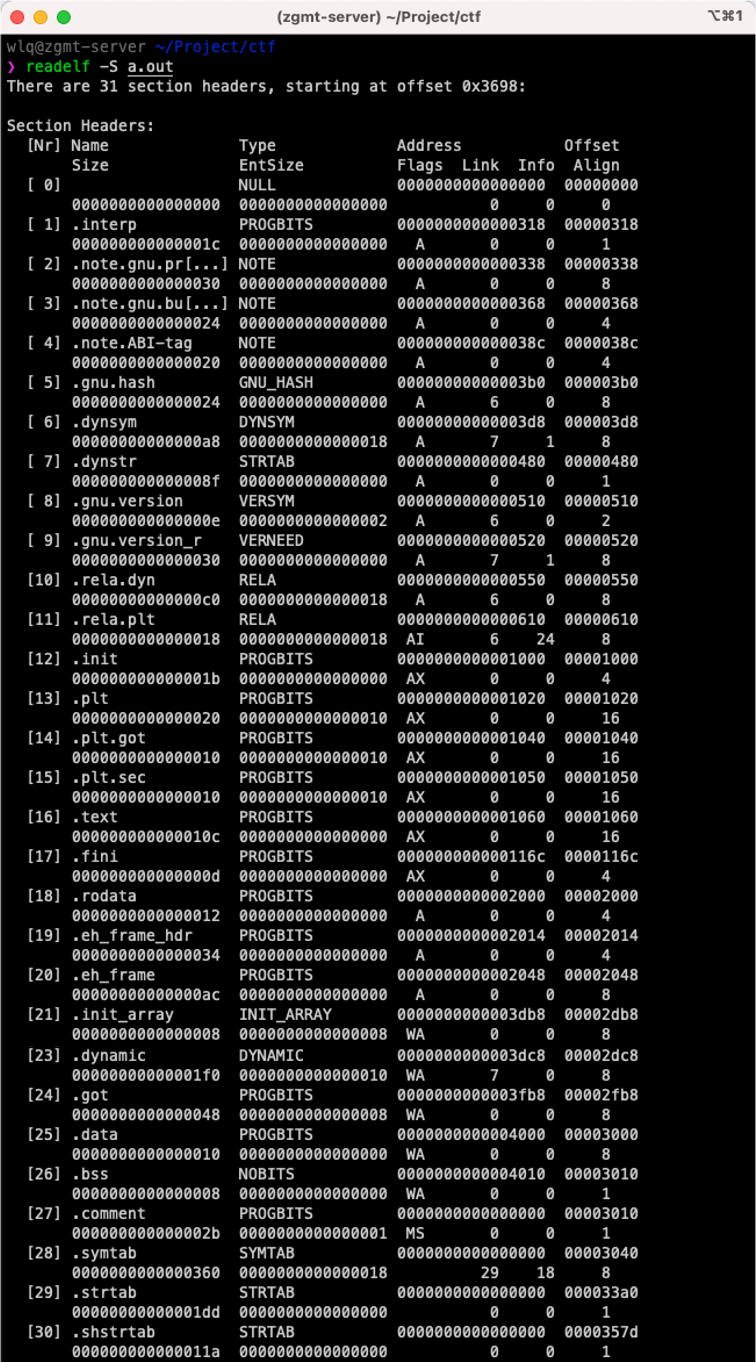
通过 readelf -S 命令来看看示例程序中的 Section Header Table 内容,如下图所示。示例程序共生成 31 个区:
- Name 表示每个区的名字
- Type 表示每个区的功能
- Address 表示每个区的进程映射地址
- Offset 表示文件内偏移
- Size 表示区的大小
- EntSize 表示区中每个元素的大小(如果该区为一个数组的话,否则该值为 0)
- Flags 表示每个区的属性(参见图中最后的说明)
- Link 和 Info 记录不同类型区的相关信息(不同类型含义不同,具体参见规范)
- Align 表示区的对齐单位。
节类型(sh_type)目前有下列可选范围,其中 SHT 是 Section Header Table 的简写。
| 名称 | 取值 | 说明 |
|---|---|---|
| SHT_NULL | 0 | 该类型节区是非活动的,这种类型的节头中的其它成员取值无意义。 |
| SHT_PROGBITS | 1 | 该类型节区包含程序定义的信息,它的格式和含义都由程序来决定。 |
| SHT_SYMTAB | 2 | 该类型节区包含一个符号表(SYMbol TABle)。目前目标文件对每种类型的节区都只 能包含一个,不过这个限制将来可能发生变化。 一般,SHT_SYMTAB 节区提供用于链接编辑(指 ld 而言) 的符号,尽管也可用来实现动态链接。 |
| SHT_STRTAB | 3 | 该类型节区包含字符串表( STRing TABle )。 |
| SHT_RELA | 4 | 该类型节区包含显式指定位数的重定位项( RELocation entry with Addends ),例如,32 位目标文件中的 Elf32_Rela 类型。此外,目标文件可能拥有多个重定位节区。 |
| SHT_HASH | 5 | 该类型节区包含符号哈希表( HASH table )。 |
| SHT_DYNAMIC | 6 | 该类型节区包含动态链接的信息( DYNAMIC linking )。 |
| SHT_NOTE | 7 | 该类型节区包含以某种方式标记文件的信息(NOTE)。 |
| SHT_NOBITS | 8 | 该类型节区不占用文件的空间,其它方面和 SHT_PROGBITS 相似。尽管该类型节区不包含任何字节,其对应的节头成员 sh_offset 中还是会包含概念性的文件偏移。 |
| SHT_REL | 9 | 该类型节区包含重定位表项(RELocation entry without Addends),不过并没有指定位数。例如,32 位目标文件中的 Elf32_rel 类型。目标文件中可以拥有多个重定位节区。 |
| SHT_SHLIB | 10 | 该类型此节区被保留,不过其语义尚未被定义。 |
| SHT_DYNSYM | 11 | 作为一个完整的符号表,它可能包含很多对动态链接而言不必 要的符号。因此,目标文件也可以包含一个 SHT_DYNSYM 节区,其中保存动态链接符号的一个最小集合,以节省空间。 |
| SHT_LOPROC | 0X70000000 | 此值指定保留给处理器专用语义的下界( LOw PROCessor-specific semantics )。 |
| SHT_HIPROC | OX7FFFFFFF | 此值指定保留给处理器专用语义的上界( HIgh PROCessor-specific semantics )。 |
| SHT_LOUSER | 0X80000000 | 此值指定保留给应用程序的索引下界。 |
| SHT_HIUSER | 0X8FFFFFFF | 此值指定保留给应用程序的索引上界。 |
节头中 sh_flags 字段的每一个比特位都可以给出其相应的标记信息,其定义了对应的节区的内容是否可以被修改、被执行等信息。如果一个标志位被设置,则该位取值为 1,未定义的位都为 0。目前已定义值如下,其他值保留。
| 名称 | 值 | 说明 |
|---|---|---|
| SHF_WRITE | 0x1 | 这种节包含了进程运行过程中可以被写的数据。 |
| SHF_ALLOC | 0x2 | 这种节在进程运行时占用内存。对于不占用目标文件的内存镜像空间的某些控制节,该属性处于关闭状态 (off)。 |
| SHF_EXECINSTR | 0x4 | 这种节包含可执行的机器指令(EXECutable INSTRuction)。 |
| SHF_MASKPROC | 0xf0000000 | 所有在这个掩码中的比特位用于特定处理器语义。 |
当节区类型的不同的时候,sh_link 和 sh_info 也会具有不同的含义。
| sh_type | sh_link | sh_info |
|---|---|---|
| SHT_DYNAMIC | 节区中使用的字符串表的节头索引 | 0 |
| SHT_HASH | 此哈希表所使用的符号表的节头索引 | 0 |
| SHT_REL/SHT_RELA | 与符号表相关的节头索引 | 重定位应用到的节的节头索引 |
| SHT_SYMTAB/SHT_DYNSYM | 操作系统特定信息,Linux 中的 ELF 文件中该项指向符号表中符号所对应的字符串节区在 Section Header Table 中的偏移。 | 操作系统特定信息 |
| other | SHN_UNDEF | 0 |
Section: STRTAB¶
从上述 Section Header Table 示例中,我们看到有一种类型为 STRTAB 的区(在 Section Header Table 中的下标为 7,29,30)。此类区叫做 String Table,其作用是集中记录字符串信息,其它区在需要使用字符串的时候,只需要记录字符串起始地址在该 String Table 表中的偏移即可,而无需包含整个字符串内容。

我们使用 readelf -x 读出下标 30 区的详细内容观察:
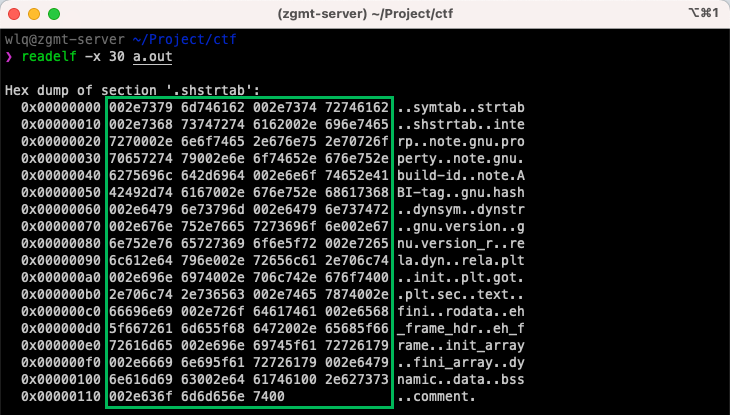
绿框内为该区实际内容,左侧为区内偏移地址,后侧为对应内容的字符表示。我们可以发现,这里其实是一堆字符串,这些字符串对应的就是各个区的名字。因此 section header table 中每个元素的 Name 字段其实是这个 string table 的索引。
再回头看看 ELF header 中的 e_shstrndx,它的值正好就是 30,指向了当前的 string table。
同理再来看下 29 区的内容,如下图所示。这里我们看到了”main”字符串,这些是我们在示例中源码中定义的符号,由此可以 29 区是应用自身的 String Table,记录了应用使用的字符串。
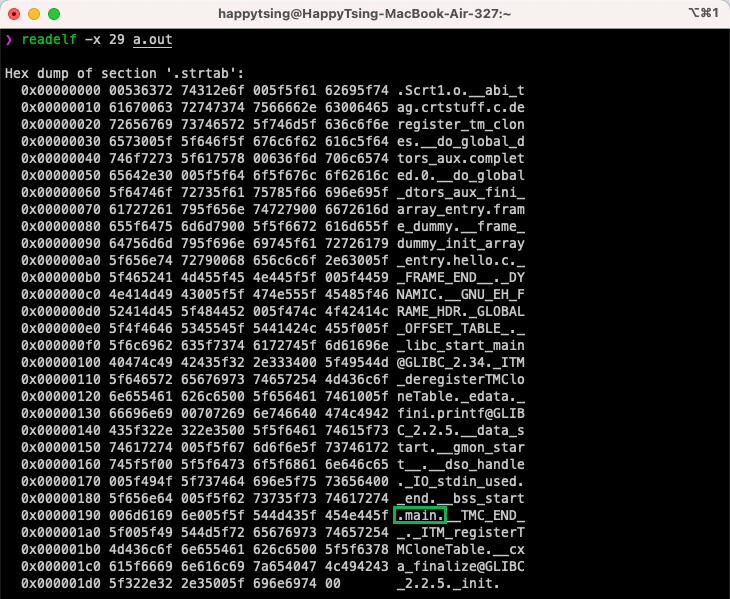
Section: SYMTAB¶
Section Header Table 中,还有一类 SYMTAB(DYNSYM)区,该区叫符号表。符号表中的每个元素对应一个符号,记录了每个符号对应的实际数值信息,通常用在重定位过程中或问题定位过程中,进程执行阶段并不加载符号表。
typedef struct {
Elf32_Word st_name;
Elf32_Addr st_value;
Elf32_Word st_size;
unsigned char st_info;
unsigned char st_other;
Elf32_Half st_shndx;
}Elf32_Sym;
符号表中每个元素定义如下:
- name 表示符号对应的源码字符串,为对应 String Table 中的索引;
- value 表示符号对应的数值;
- size 表示符号对应数值的空间占用大小;
- info 表示符号的相关信息,如符号类型(变量符号、函数符号);
- shndx 表示与该符号相关的区的索引,例如函数符号与对应的代码区相关。
我们用 readelf -s 读出示例程序中的符号表,如下图所示。如红框中内容所示,我们示例程序定义的 main 函数符号的类型为 FUNC,大小为 35 字节,对应的代码区在 Section Header Table 中的索引为 16
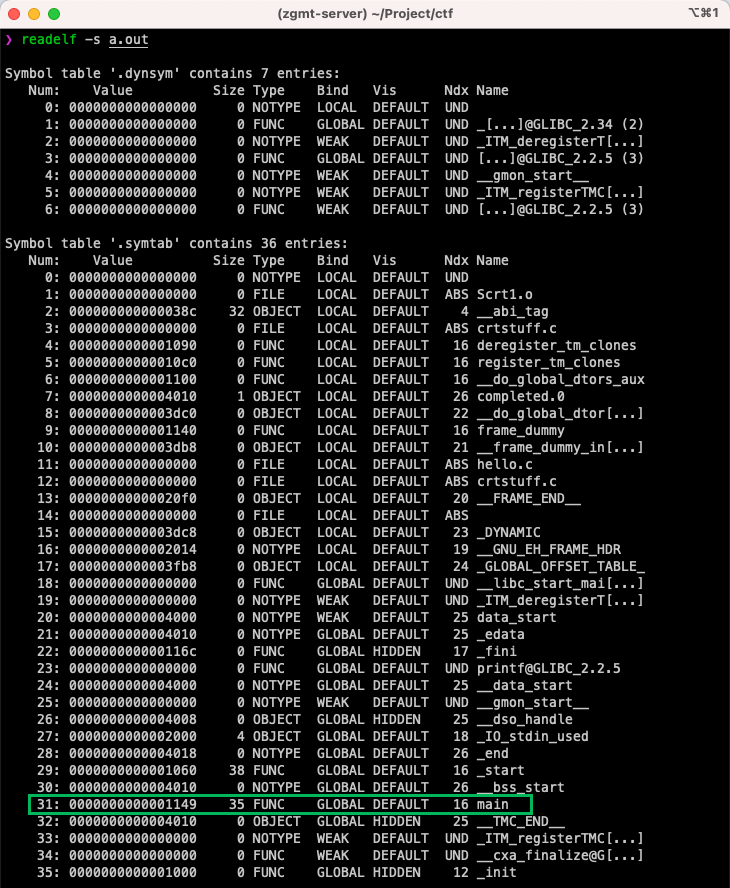
反汇编实例¶
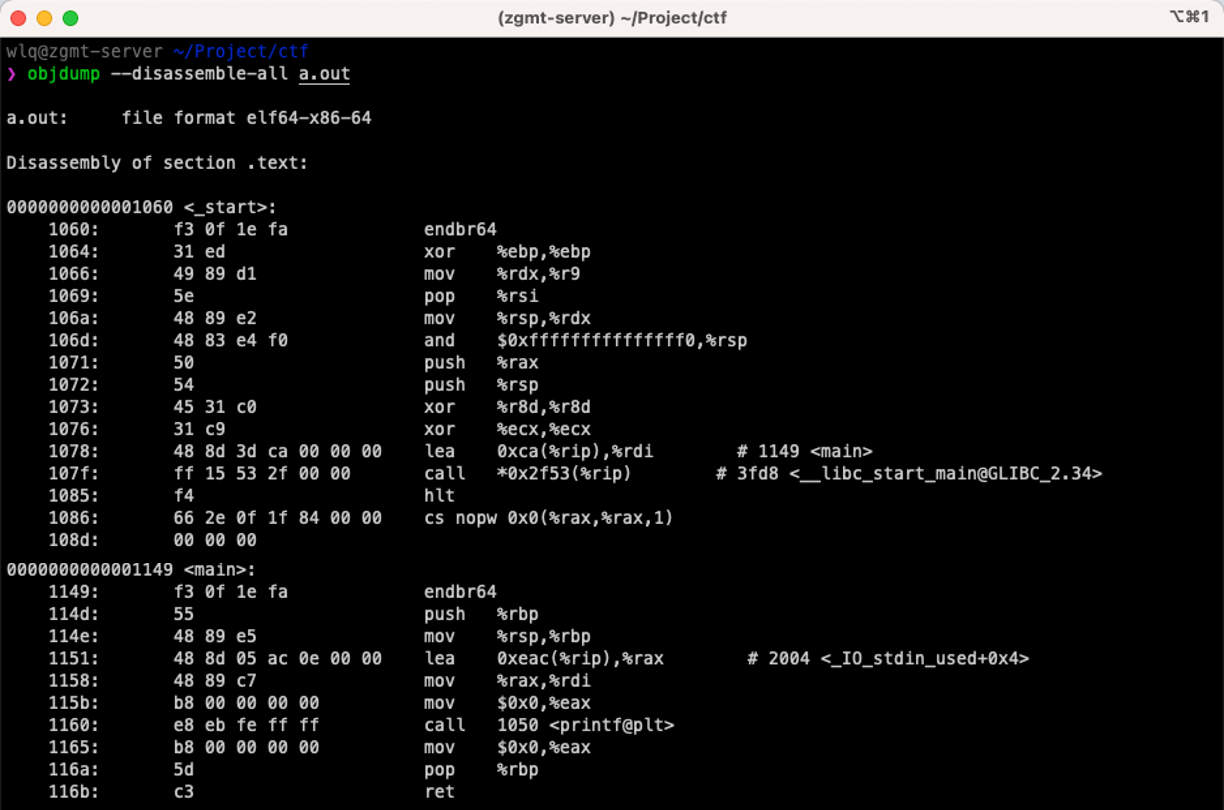
此处仅展示了 .text 节的部分内容,可以看到在 0x1149 地址 处定义了函数 ,其符号为 main,这部分信息实际是通过符号表解析而来的。
中间为二进制形式,最右侧为对应的汇编指令,例如 0x48 其对应的汇编指令为 mov。