深入理解计算机系统
Quote
2024.1.11 硕二年级于清水河寝,梳理计算机基础
—— 博观而约取,厚积而薄发
根据《深入理解计算机系统》的组织顺序,首先需要理解 信息的表示和处理,即十六进制、整数、浮点数的表示等信息,随后描述了 程序的机器级表示,介绍了 8086 以及其后代 X86、x86-64 的由来,引入 二进制和汇编代码,从底层角度讲解程序指令的执行。
接着,将介绍处理器体系结构和存储器层次结构。
最后,关注程序在系统上的运行,首先介绍 编译、链接及 ELF 文件格式,接着讲解 可执行目标文件的加载和执行。随后将对 异常控制流 进行介绍,主要是 中断和系统调用,并引入 进程 的概念。其次,介绍 虚拟内存 及其分配回收。
当然,可能还会涉及 IO 及 并发 的内容。
目标文件与 ELF¶
Linux 下的可执行文件格式:ELF¶
参考:
通过 file 指令查看文件的格式,以此判断是否是 ELF 格式的文件:
在现在 Linux/Unix 系统中,使用可执行可链接格式(ELF, Executable and Linkable Format) 表示目标文件,类似的,Windows 采用可移植可执行(PE, Portable Executable),Mac 使用 Mach-O 格式表示。
目标文件主要有以下三种类型
- 可重定位目标文件(Relocatable File):包含二进制代码和数据,其形式可以在编译时与其他可重定位目标文件合并起来,创建一个可执行目标文件。Linux
系统中的后缀为
.o。 - 可执行目标文件(Executable File):包含二进制代码和数据,其形式可以被 直接复制到内存并执行。
- 共享目标文件(Shared Object File):一种 特殊的可重定位目标文件
,可以在加载或者运行时被动态的加载进内存并链接。一般称为库文件,后缀为
.so
根据 ELF 类型的不同,其文件内包含的内容也不同,主要分为可重定位目标文件和可执行目标文件两类:
可重定位目标文件¶
图示为典型的 ELF 可重定位目标文件的格式:
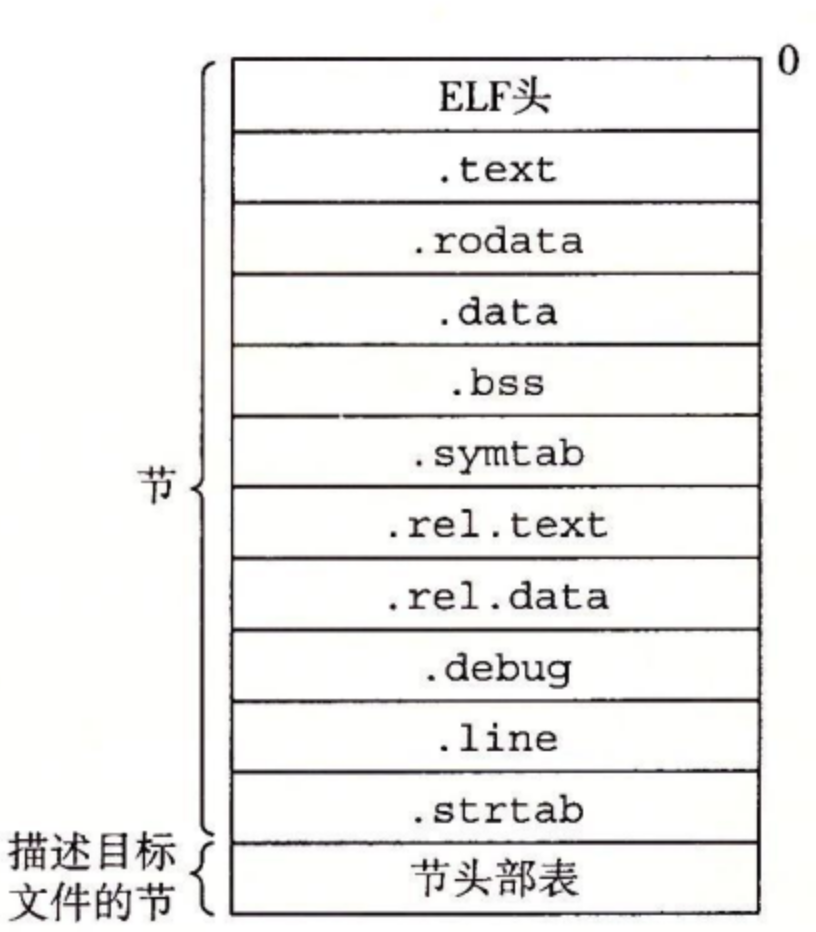
① ELF Header :
- 以 16 字节的序列开始,该序列描述了生成该文件的系统的字的大小和字节顺序。
- 剩下的部分包含帮助链接器语法分析和解释目标文件的信息: ELF 头的大小、目标文件的类型(如可重定位、可执行或者共享的)、机器类型(如 x86-64)、节头部表(section header table)的文件偏移,以及节头部表中条目的大小和数量。
② Section Header Table :不同节的位置和大小是由节头部表描述的,其中目标文件中每个节都在节头部表中有一个固定大小的 条目(entry)。
③ Section :夹在 ELF 头和节头部表之间的都是节,一个典型的 ELF 可重定位目标文件包含下面几个节:
-
.text: 已编译程序的机器代码。
-
.rodata: 只读数据,比如 printf 语句中的格式串和开关语句的跳转表。
-
.data: 已初始化的全局和静态 C 变量。局部 C 变量在运行时被保存在栈中,既不岀现在 .data 节中,也不岀现在 .bss 节中。
-
.bss: 未初始化的全局和静态 C 变量,以及所有被初始化为 0 的全局或静态变量。在目标文件中这个节不占据实际的空间,它仅仅是一个占位符。目标文件格式区分已初始化和未初始化变量是为了空间效率:在目标文件中,未初始化变量不需要占据任何实际的磁盘空间。运行时,在内存中分配这些变量,初始值为 0。
-
.symtab: 一个符号表,它存放在程序中定义和引用的函数和全局变量的信息。一些程序员错误地认为必须通过 -g 选项来编译一个程序,才能得到符号表信息。实际上,每个可重定位目标文件在 .symtab 中都有一张符号表(除非程序员特意用 STRIP 命令去掉它)。然而,和编译器中的符号表不同,.symtab 符号表不包含局部变量的条目。
-
.rel.text: 一个 .text 节中位置的列表,当链接器把这个目标文件和其他文件组合时,需要修改这些位置。一般而言,任何调用外部函数或者引用全局变量的指令都需要修改。另一方面,调用本地函数的指令则不需要修改。注意,可执行目标文件中并不需要重定位信息,因此通常省略,除非用户显式地指示链接器包含这些信息。
-
.rel.data: 被模块引用或定义的所有全局变量的重定位信息。一般而言,任何已初始化的全局变量,如果它的初始值是一个全局变量地址或者外部定义函数的地址,都需要被修改。
-
.debug: 一个调试符号表,其条目是程序中定义的局部变量和类型定义,程序中定义和引用的全局变量,以及原始的 C 源文件。只有以 - g 选项调用编译器驱动程序时,才 会得到这张表。
-
.line: 原始 C 源程序中的行号和 .text 节中机器指令之间的映射。只有以 -g 选项调用编译器驱动程序时,才会得到这张表。
-
.strtab: 一个字符串表,其内容包括 .symtab 和 .debug 节中的符号表,以及节头部中的节名字。字符串表就是以 null 结尾的字符串的序列。
为什么未初始化的数据称为 .bss?
用术语 .bss 来表示未初始化的数据是很普遍的。它起始于 IBM 704 汇编语言(大约在 1957 年)中“块存储开始(Block Storage Start)”指令的首字母缩写,并沿用至今。一种记住 .data 和 .bss 节之间区别的简单方法是把 “bss” 看成是“更好地节省空间(Better Save Space)” 的缩写。
可执行目标文件¶
链接器将多个目标文件合并成一个可执行目标文件。我们的示例 C 程序,开始时是一组 ASCII 文本文件,现在已经被转化为一个二进制文件,且这个二进制文件包含加载程序到内存并运行它所需的所有信息。
在二进制目标文件中,多个节可以被看做一个段,我们主要关注两种段,后续会被加载到内存中:
- Text:代码段,包含 ELF Header、Program Header Table、.init、.text、.rodata
- Data:数据段,包含 .data、.bss
图示为典型的 ELF 可执行目标文件的格式:
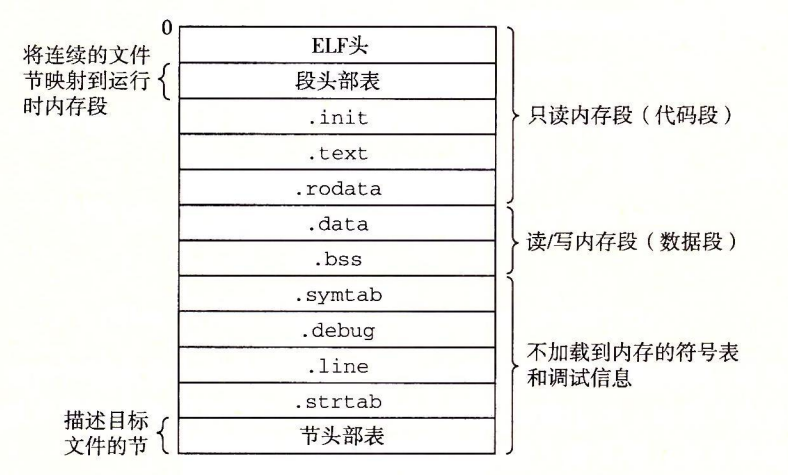
可执行目标文件的格式类似于可重定位目标文件的格式。ELF 头描述文件的总体格式。它还包括程序的 入口点(entry point),也就是当程序运行时要执行的第一条指令的地址。
- .text、.rodata 和 .data 节与可重定位目标文件中的节是相似的,除了这些节已经被重定位到它们最终的运行时内存地址以外。
- .init 节定义了一个小函数,叫做 _init,程序的初始化代码会调用它。
- 因为可执行文件是 完全链接的(已被重定位),所以它不再需要 .rel 节。
ELF 可执行文件被设计得很容易加载到内存,可执行文件的连续的片(chunk)被映射到连续的内存段。程序头部表(program header table)描述了这种映射关系。
下面展示可执行文件 prog 的程序头部表,是由 OBJDUMP 显示的:
Read-only code segment
LOAD off 0x0000000000000000 vaddr 0x0000000000400000 paddr 0x0000000000400000 align 2**21
filesz 0x000000000000069c memsz 0x00000oo000o0069c flags r-x
Read/write data segment
LOAD off 0x0000000000000df8 vaddr 0x0000000000600df8 paddr 0x0000000000600df8 align 2**21
filesz 0x0000000000000228 memsz 0x0000000000000230 flags rw-
off:目标文件中的偏移;vaddr/paddr:内存地址;align:对齐要求;filesz:目标文件中的段大小;memsz:内存中的段大小;flags:运行时访问权限。
从程序头部表,我们会看到根据可执行目标文件的内容初始化两个内存段。
-
第 1 行和第 2 行告诉我们第一个段(代码段)有读/执行访问权限,开始于内存地址 0x400000 处,总共的内存大小是 0x69c 字节,并且被初始化为可执行目标文件的头 0x69c 个字节,其中包括 ELF 头、程序头部表以及 .initx.text 和 .rodata 节。
-
第 3 行和第 4 行告诉我们第二个段(数据段)有读/写访问权限,开始于内存地址 0x600df8 处,总的内存大小为 0x230 字节,并用从目标文件中偏移 0xdf8 处开始的 .data 节中的 0x228 个字节初始化。该段中剩下的 8 个字节对应于运行时将被初始化为 0 的 .bss 数据。
对于任何段 s,链接器必须选择一个起始地址 vaddr,使得 \(vaddr\ mod\ align = off\ mod\ align\)
- off 是目标文件中段的第一个节的偏移量
- align 是程序头部中指定的对齐 \(2^{21} = 0x200000\)。
上例的数据段中:\(vaddr\ mod\ align = 0x600df8\ mod\ 0x200000 = 0xdf8\)
以及:\(off\ mod\ align = 0xdf8\ mod\ 0x200000 = 0xdf8\)
这个对齐要求是一种优化,使得当程序执行时,目标文件中的段能够很有效率地传送到内存中。原因有点儿微妙,在于虚拟内存的组织方式,它被组织成一些很大的、连续的、大小为 2 的幂的字节片。
处理目标文件的工具¶
在 Linux 系统中有大量可用的工具可以帮助你理解和处理目标文件。特别地,GNU binutils 包尤其有帮助,而且可以运行在每个 Linux 平台上。
- AR:创建静态库,插入、删除、列出和提取成员。
- STRINGS:列出一个目标文件中所有可打印的字符串。
- STRIP:从目标文件中删除符号表信息。
- NM:列出一个目标文件的符号表中定义的符号。
- SIZE:列出目标文件中节的名字和大小。
- READELF:显示一个目标文件的完整结构,包括 ELF 头中编码的所有信息。包含 SIZE 和 NM 的功能。
- OBJDUMP:所有二进制工具之母。能够显示一个目标文件中所有的信息。它最大的作用是反汇编 .text 节中的二进制指令。
Linux 系统为操作共享库还提供了 LDD 程序:
- LDD:列出一个可执行文件在运行时所需要的共享库。
编译与链接¶
C Example¶
以 C 语言程序 hello.c 为例(参考 CSAPP):

-
预处理阶段。 预处理器(cpp)根据以字符 ## 开头的命令,修改原始的 C 程序。比如 hello.c 中第 1 行的
#include <stdio.h>命令告诉预处理器读取系统头文件 stdio.h 的内容,并把它直接插入程序文本中。结果就得到了另一个 C 程序,通常是以 .i 作为文件扩展名。 -
编译阶段。 编译器(ccl)将文本文件 hello.i 翻译成文本文件 hello.s,它包含一个 汇编语言程序。该程序包含函数 main 的定义,如下所示 ∶
定义中 2 ~ 7 行的每条语句都以一种文本格式描述了一条低级机器语言指令。汇编语言是非常有用的,因为它为不同高级语言的不同编译器提供了通用的输出语言。例如,C 编译器和 Fortran 编译器产生的输出文件用的都是一样的汇编语言。
- 汇编阶段。 接下来,汇编器(as)将 hello.s 翻译成机器语言指令,把这些指令打包成一种叫做 可重定位目标程序(relocatable object program)的格式,并将结果保存在目标文件 hello.o 中。hello.o 文件是一个二进制文件,它包含的 17 个字节是函数 main 的指令编码。如果我们在文本编辑器中打开 hello.o 文件,将看到一堆乱码。
注意 .o 又被称为目标代码文件,是机器代码的一种形式,包含所有指令的二进制表示,但还没有填入全局值的地址。(CSAPP P113)
- 链接阶段。 请注意,hello 程序调用了 printf 函数,它是每个 C 编译器都提供的标准 C 库中的一个函数。printf 函数存在于一个名为 printf.o 的单独的预编译好了的目标文件中,而这个文件必须以某种方式合并到我们的 hello.o 程序中。链接器(ld)就负责处理这种合并。结果就得到 hello 文件,它是一个 可执行目标文件(或者简称为 可执行文件),可以被加载到内存中,由系统执行。
此处仅介绍 Windows 和 Linux 下的二进制文件。
Windows:PE(Portable Executable)
- 可执行程序文件:
.exe - 动态链接库文件:
.dll - 静态链接库文件:
.lib
LInux:ELF(Executable and Linkable Format)
- 可执行程序文件:
.out - 动态链接库文件:
.so - 静态链接库文件:
.a
静态链接与静态库¶
静态链接:类似 Linux LD 这样的静态连接器以 一组可重定位目标文件 和命令参数作为输入,生成一个完全链接的、可以加载和运行的可执行目标文件作为输出。注意 静态链接生成的文件包含了运行时所需的全部代码,当多个可执行目标文件调用相同的函数时,内存中就会存在这个函数的多个拷贝,浪费宝贵的内存资源。
为了构造可执行文件,链接器必须完成两个主要任务:
- 符号解析:目标文件定义和引用符号,每个符号对应于一个函数、全局变量或静态变量。
- 重定位:编译器和汇编器生成从地址 0 开始的代码和数据节,链接器将多个文件合并时,需要重定位节的地址,并且修改符号引用,使其指向新地址
静态库:注意到谈及静态链接时,我们假设链接器读取一组可重定位目标文件,并将其链接起来。但实际上,编译系统均为提供一种机制,将所有相关的目标文件打包成为一个单独的文件,称为静态库,静态库文件以 .a 结尾,用作链接器的输入。
例如:
- libc 是 C 语言程序开发中最基础的库之一,也是其他高级库和框架的基础。libc.a 约 5MB
- libm 是数学库,包含了许多数学函数,例如三角函数、对数函数、指数函数等。libm.a 约 2MB
本质上 libc.a 中就是一系列 .o 文件,但实际上当使用静态库时,链接器将只复制被程序引用的目标模板,这就减少了静态链接后可执行文件在磁盘和内存中的大小。
此外,程序员只需要包含较少的静态库就行,而不需要包含大量的 .o 文件(实际上,C 编译器驱动总是传送 libc.a 给链接器,因此不需要手动引用静态库 libc.a。
在 Linux 中,静态库以一种称为 存档(archive) 的特殊文件格式存放在磁盘中,本质上是一组连接起来的可重定位目标文件的集合,有一个头部用来描述每个成员目标文件的大小和位置,存档文件名由后缀.a 标识。
例(CSAP 477):假设有两个文件 addvec.c、multvec.c,分别提供加法和减法函数,将其创建为一个静态库:
gcc -c advec.c multvec.c ## -c 只激活预处理、编译和汇编,文件将被汇编成为可重定位目标文件 .o
ar rcs libvector.a addvec.o multvec.o ## AR 工具生成静态库
假设 vector.h 头文件中定义了 libvector.a 中的函数原型,如果想使用该库提供的函数:
#include "vector.h"
#include <stdio.h>
int main()
{
addvec(...); // addvec.c 中的函数
printf(...);
return 0;
}
最后一步,在链接时,提供该静态库:
1. gcc -c main2.c
2. gcc -static -o prog2c main2.o ./libvector.a ## -static 选项将禁止使用动态库
2. gcc -static -o prog2c main2.0 -L. -lvector ## 等价上句
首先,通过第一句将 main2.c 经过预处理、编译和汇编处理后成为可重定位目标文件 main.o,接着:
- -static:关闭动态库,高速编译器驱动程序,链接器应该构建一个完全链接的可执行目标文件,它可以加载到内存中运行,且在加载时无须更进一步的链接
- -o prog2c:指定生成的可执行目标文件为 prog2c
- -lvector 参数是 libvector.a 的缩写, -L. 参数告诉链接器在 当前目录下查找 libvector.a
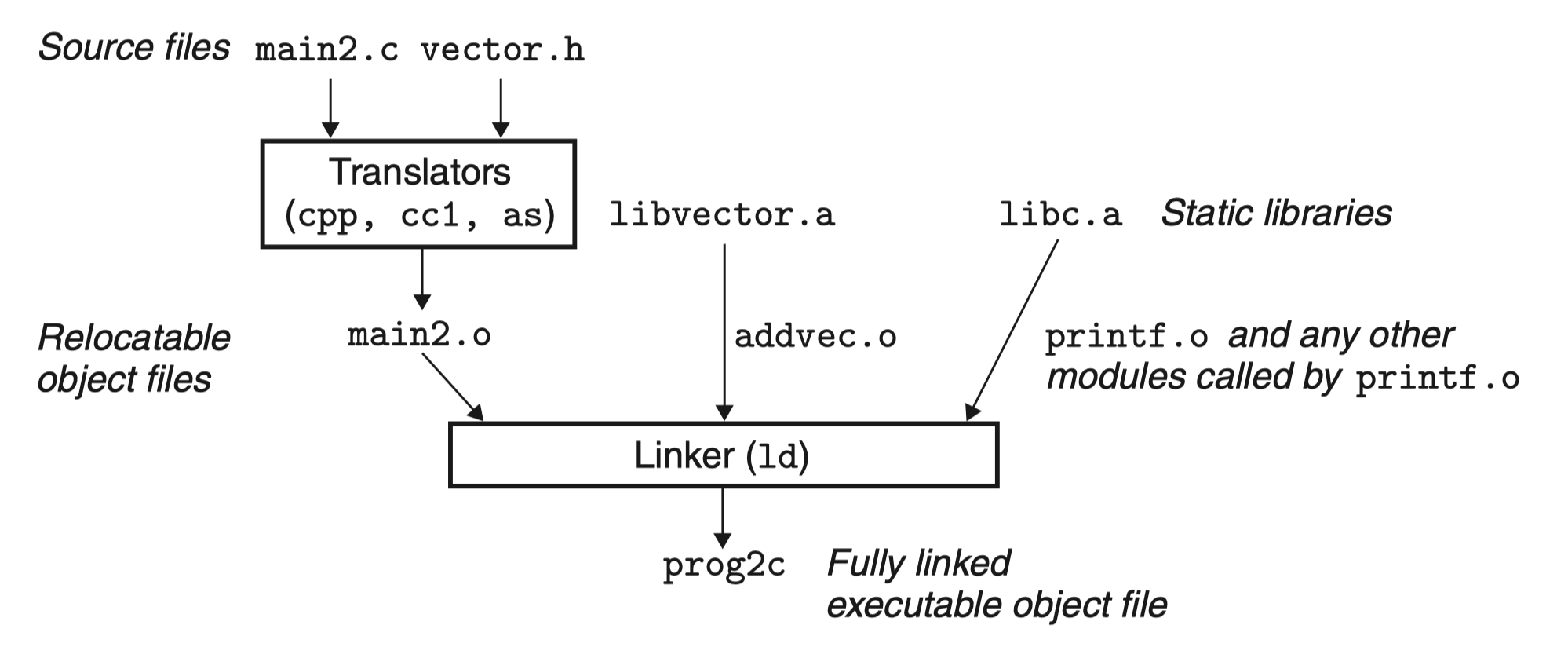
注意 libc.a 由 C 编译器驱动程序自动传送给链接器,此处会将 libc.a 中的 printf.o 模块复制到可执行文件中,以及许多 C 运行时系统中的其他模块。
链接器还会判定 mian2.o 引用了 addvec.o 定义的 addvec 符号,所以复制 addvec.o 到可执行文件,但程序没有引用任何 multvec.o 定义的符号,因此 multvec.o 不会复制到可执行文件中。
动态链接和共享库¶
动态链接 是相对静态链接而言的,动态链接所调用的函数代码并没有被拷贝到应用程序的可执行文件中去,而是仅仅 在其中加入了所调用函数的描述信息(往往是一些重定位信息)。仅当应用程序被装入内存开始运行时,才在应用程序与相应的动态链接库文件之间建立链接关系。
共享库
静态库主要存在两个问题:
- 更新维护:由于静态库必然要实时更新,如果程序员想要使用一个库的最新版本,必须获取库的最新版,然后显式地将程序与更新的库重新链接
- 重复占用内存:内存始终是稀有资源,例如几乎每个程序都会使用标准 I/O 函数(printf...),静态链接时,这些函数的代码会被复制到每个运行进程的文本段中
共享库(shared library)是致力于解决静态库缺陷的一个现代创新产物。共享库是一个目标模块,在运行或加载时,可以加载到任意的内存地址,并和一个在内存中的程序链接起来,该过程称为动态链接(dynamic linking),由动态链接器(dynamic linker)执行。
共享库也被称为共享目标(share target),通常用 .so 后缀。
- -shared 指示链接器创建一个共享的目标文件
- -fpic 指示编译器生成与位置无关的代码
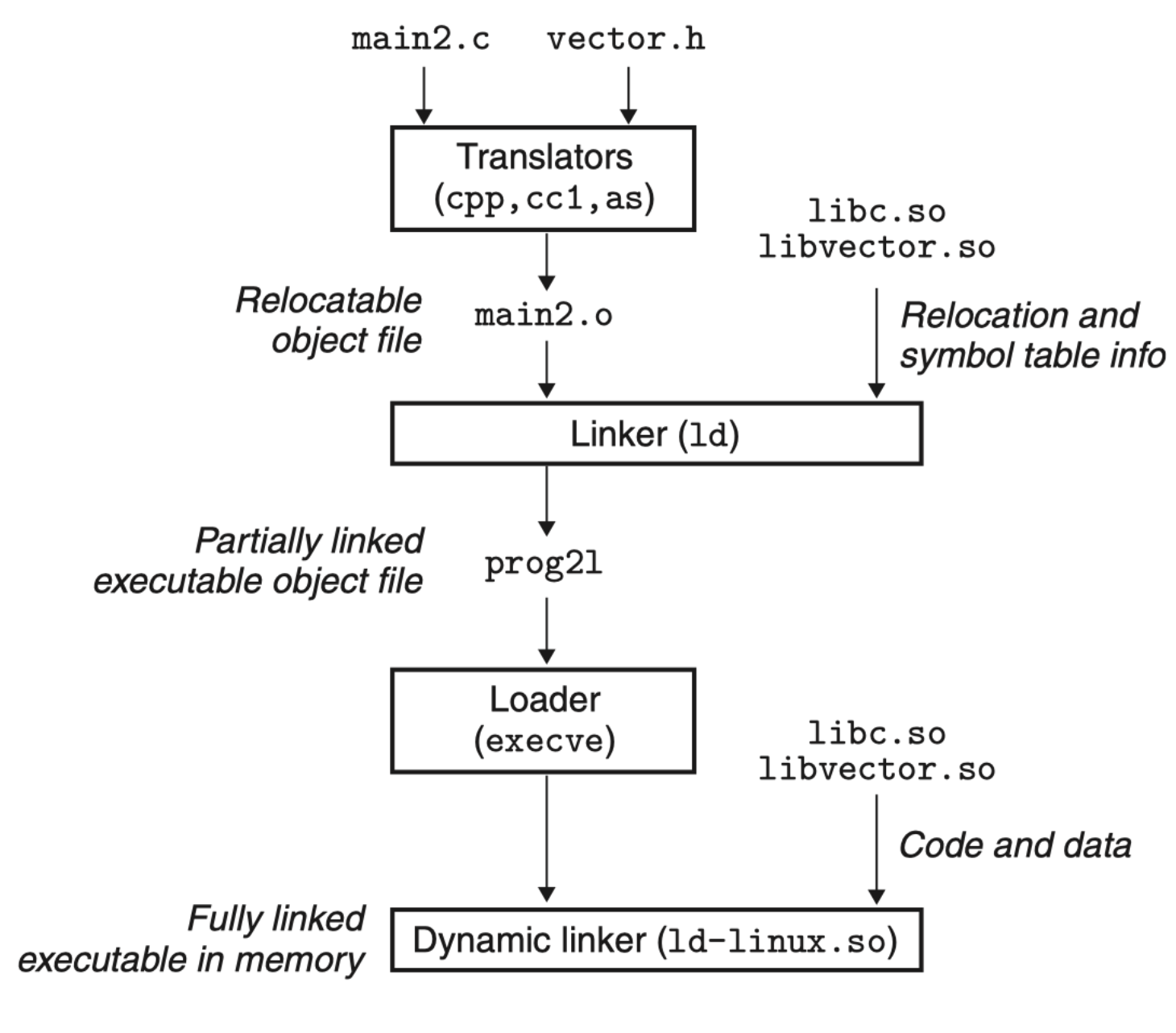
值得注意的两点,首先,在任何给定的文件系统中,对于一个库只有一个 .so 文件,所有引用该库的可执行目标文件共享该 .so 文件中的代码和数据,而不是像静态库的内容那样被复制和嵌入到引用它们的可执行文件中。其次,在内存中,一个共享库的 .text 节的一个副本可以被不同的正在运行的进程共享。
PLT&GOT¶
用于延迟绑定,参考:https://www.yuque.com/hxfqg9/bin/ug9gx5
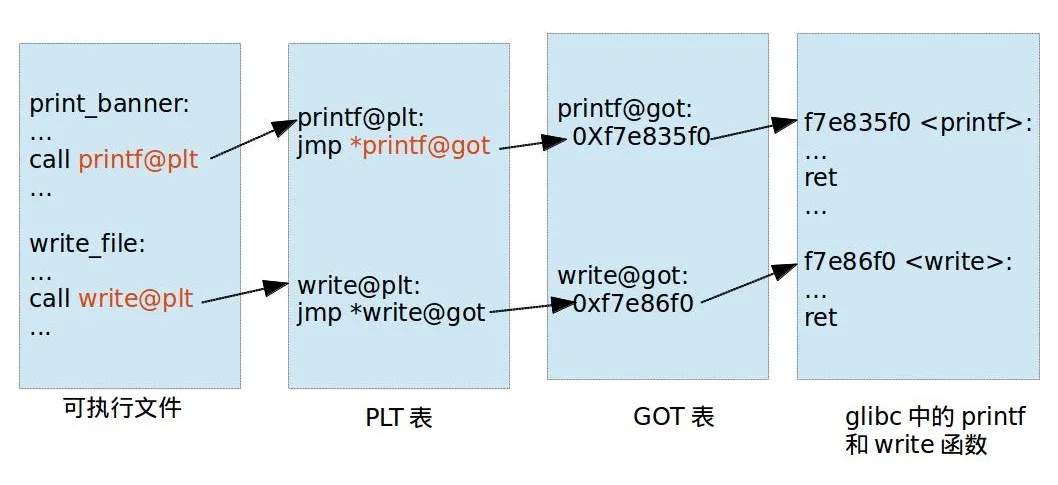
对应 PLT 地址指向的是 GOT 的地址,GOT 表指向的就是 printf 函数具体代码位置。
什么是延迟绑定呢?只有动态库函数在被调用时,才会地址解析和重定位工作。
一开始,printf@got 是 lookup_printf 函数的地址,这个函数用来寻找 printf() 的地址,然后写入 printf@got,lookup_printf 执行完毕后就找到了,然后记录到 got 表中,此后就不再需要找了!
程序的机器级表示:x86/amd 汇编¶
1978 年的 8086 处理器是 16 位处理器,1985 年因特尔发布 i386 将体系扩展到 32 位。因特尔处理器系列有很多名字,包括 IA32(Intel Architecture 32-bit),通常都将 32 位的称为 X86 。
随后在向 64 位过度的时候,因特尔发布 IA64,由于与原来的 X86 架构不兼容,市场反应极差,此时 AMD 率先搞出了与原 X86 兼容的 64 位处理器,称为 x86-64,也叫 AMD64。
由于 x86-64 与原 X86 兼容,此处主要介绍 x86-64,也就是 AMD64。
需要注意的是,32 位和 64 位程序有以下简单的区别
-
x86
- 函数参数 会被优先压入栈中,然后才将 函数返回地址 压入栈
-
x64
-
System V AMD64 ABI (Linux、FreeBSD、macOS 等采用) 中前六个整型或指针参数依次保存在 RDI, RSI, RDX, RCX, R8 和 R9 寄存器 中,如果还有更多的参数的话才会保存在栈上。
-
内存地址不能大于 0x00007FFFFFFFFFFF,6 个字节长度,否则会抛出异常。
参见:CSAPP P114
高 16 位地址必须为 0 ,因此实际上目前的 64 位系统是 48 位系统,但可以随时扩展到 64 位!
-
ATT 风格指令参考 CSAPP 第三章。
机器级代码通常指二进制代码和汇编代码,后者十分接近二进制代码,可读性更高,值得注意的是,机器级代码只是简单的将内存看成一个很大的、按字节寻址的数组。x86-64 的虚拟地址是按 64 位的字来标识的,但在目前的实现中,高 16 位必须为 0,也就是说,实际地址范围为 \(2^{48}\) (256TB),但可随时扩展。
获取汇编代码的方式有两种:
- 源代码->汇编代码:
gcc -Og -S hello.c - 二进制代码->汇编代码:
objdump -d hello
通过 objdump 反汇编得到的汇编指令与 GCC 生成的汇编代码可能存在细微差别,例如 call 与 callq,但大部分情况下可以忽略。
由于最早是从 16 位体系结构扩展为 32 位,因此 Intel 用术语 字(word) 表示 16 位字节,于是称 32 位为 双字(doubles words)
,称 64 位为 四字(quad words)。
通常,b、w、l、q 后缀分别用于表示字节、字、双字和四字,因此在大多数 GCC 生成的汇编代码指令都有字符后缀,例如:movb(传输字节)、movq(传输四字)。
寄存器¶
整数寄存器¶
每个 x86-64 的中央处理单元(CPU)包含一组 16 个存储 64 位值的 通用目的寄存器,用于存储整数数据和指针。
图示显示了这 16 个寄存器,名字都以 %r 开头,这是由于指令集历史演化造成的。
-
最初的 8086 中有 8 个 16 位的寄存器,即图中的 %ax 到 %bp,每个寄存器都有特殊的用途,名字就反映了这些不同的用途。
-
扩展到 IA32 架构时,寄存器也扩展成 32 位寄存器,标号从 %eax 到 %ebp。
- 扩展到 x86-64 后,原来的 8 个寄存器扩展成 64 位,标号从 %rax 到 %rbp。此外还新增 8 个新的寄存器,其标号是按照新的命名规则制定的:从 %r8 到 %r15。
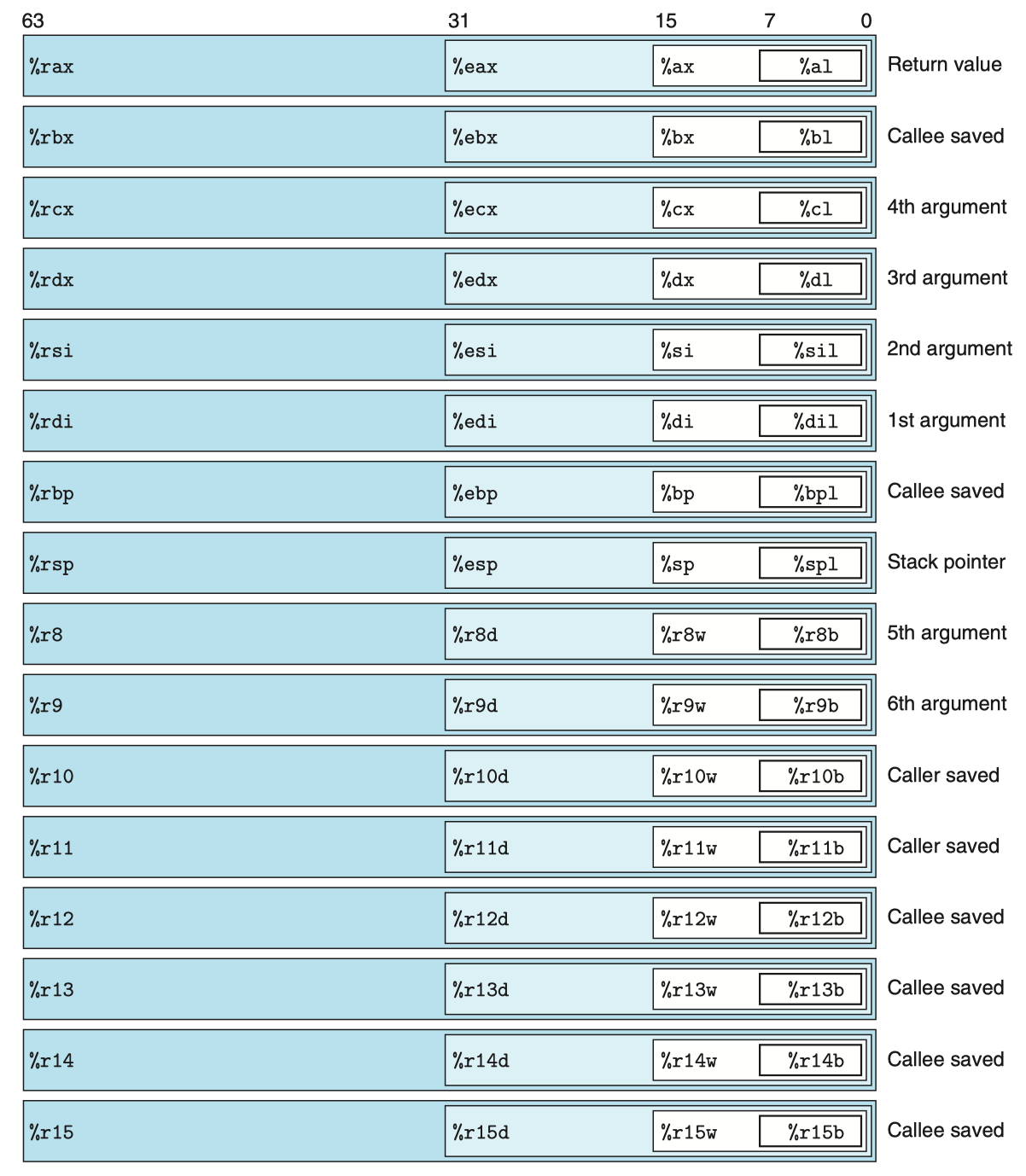
正如图中嵌套的方框标明的,指令可以对这 16 个寄存器的低位字节中存放的不同大小的数据进行操作。字节级操作可以访问最低的字节,16 位操作可以访问最低的 2 个字节,32 位操作可以访问最低的 4 个字节,而 64 位操作可以访问整个寄存器。
-
%rsp:栈顶指针,用来指明运行时栈的结束位置
-
%rax:保存函数的返回值
-
%rdi, %rsi, %rdx, %rcs, %r8, %r9:但函数 P 调用函数 Q 时,假设 Q 有 n>6 个参数,前 6 个参数的值会按顺序依次存储到上述寄存器中
-
被调用者保存寄存器:%rbx, %rbp, %r12, %r13, %r14, %r15
%rbp:栈帧指针,用于标识当前栈帧的起始位置
当函数 P 调用函数 Q,Q 作为被调用者必须保证在 Q 返回到 P 时,上述寄存器的值不变。也就是说,Q 要么根本不去更改它,要么就是把原始的值压入栈中,改变寄存器的值,然后在返回前从栈中弹出旧值。
此处压入栈的值会在栈帧中穿件标号为“被保存的寄存器“的一部分。
- 所有其他的寄存器,除了栈指针 %rsp,均为 调用者保存寄存器,包含未提及的 %r10 和 %r11。顾名思义,当 P 调用 Q,Q 可以任意修改,因为在调用之前首先保存好这些寄存器的值是 P(调用者)的责任。
除上述 16 个整数寄存器外,还有其它类型的寄存器,例如程序计数器寄存器 %rip 记录了下一条将执行的指令的地址。
条件码寄存器¶
参考《指令、操作数、控制》章节的控制章节。
指令、操作数、控制¶
操作数
大多指令由一个或多个操作数,指示出执行一个操作要使用的源数据值,以及放置结果的目的位置,分为三种类型:
- 立即数:书写方式是 \(\$\) 后面跟一个整数,例如 \(\$0x1F\)
- 寄存器:通过符号 \(r_a\)表示任意寄存器 \(a\),用引用 \(R[r_a]\) 表示寄存器的值。此处我们将寄存器集合看成数组 \(R\),用寄存器标识符作为索引。
- 内存引用:根据计算出的地址访问某个内存位置,因为将内存看成一个很大的字节数组,通过符号 \(M_b[Addr]\) 表示对存储在内存中从地址 \(Addr\) 开始的 b 个字节值的引用,为了方便,通常省略下标 \(b\)
此外,由于存在不同的 寻址模式:立即数寻址、寄存器寻址、绝对寻址等,因此通常需要组合上述三种寻址方式,具体参见 CSAPP P121。
指令(AT&T 风格)
-
数据传送指令:MOV S, D
-
压入和弹出栈数据:pushq S、pop D
-
算术和逻辑操作:加减乘除、移位、逻辑、加载有效地址(leaq S, D)
leaq 指令实际上是 movq 指令的变形,形式上看从内存读数据到寄存器,但实际上不是引用内存,而是 将有效地址写入到目的操作数 ,因此 leaq 指令的作用是加载有效地址。
- 控制:上述指令均为直线代码,即指令一条一条按序指向,实际上 C 代码中会有控制语句而导致跳转。
控制
通常来说,C 语言中的语句和机器代码中的指令都是按照它们在程序中出现的次序,顺序执行。但某些结构,比如条件语句、循环语句和分支语句,要求有条件的执行,根据数据测试的结果来决定操作执行的顺序。
为什么实现上述功能,CPU 维护着一组单个位的 条件码(condition code)寄存器 ,它们描述了最近的算术或逻辑操作的属性。可以检测这些寄存器来执行条件分支指令,常用的条件码有:
- CF:进位标志。最近的操作使最高位产生了进位。可用来检测无符号操作的溢出
- ZF:零标志。最近的操作得出的结果为 0
- SF:符号标志。最近的操作得到的结果为负数
- OF:溢出标志。最近的操作导致一个补码溢出——正溢出/负溢出
那我们如何访问条件码呢?
当调用某些指令时,指令会自动根据操作码的情况做出相应的操作,例如 SET、JGE 指令等。
☆ 过程与运行时栈(栈帧)¶
过程
过程是软件中一种重要的抽象,在不同的编程语言中,表现形式不同,诸如:function、method、subruntime、handler 等,但有相同的共有特性。
本文中以函数代替过程讲解!
假设 过程 P 调用过程 Q,Q 执行后返回到 P。上述动作包含如下机制:
- 传递控制:在进入过程 Q 的时候,程序计数器 PC 必须被设置为 Q 的代码的起始地址,然后在 Q 执行完返回 P 的时候,将 PC 设置为 P 中调用 Q 后面那条指令的地址。
- 传递数据:P 必须能够向 Q 提供一个或多个参数,Q 必须能够向 P 返回一个值
- 分配和释放内存:在开始时,Q 可能需要为局部变量 在栈上分配空间,而在 Q 执行完毕返回前,又必须释放这些存储空间。
运行时栈(C 语言)
大多数语言(以 C 为例)的关键特性为使用栈数据结构提供的后进先出的内存管理原则。
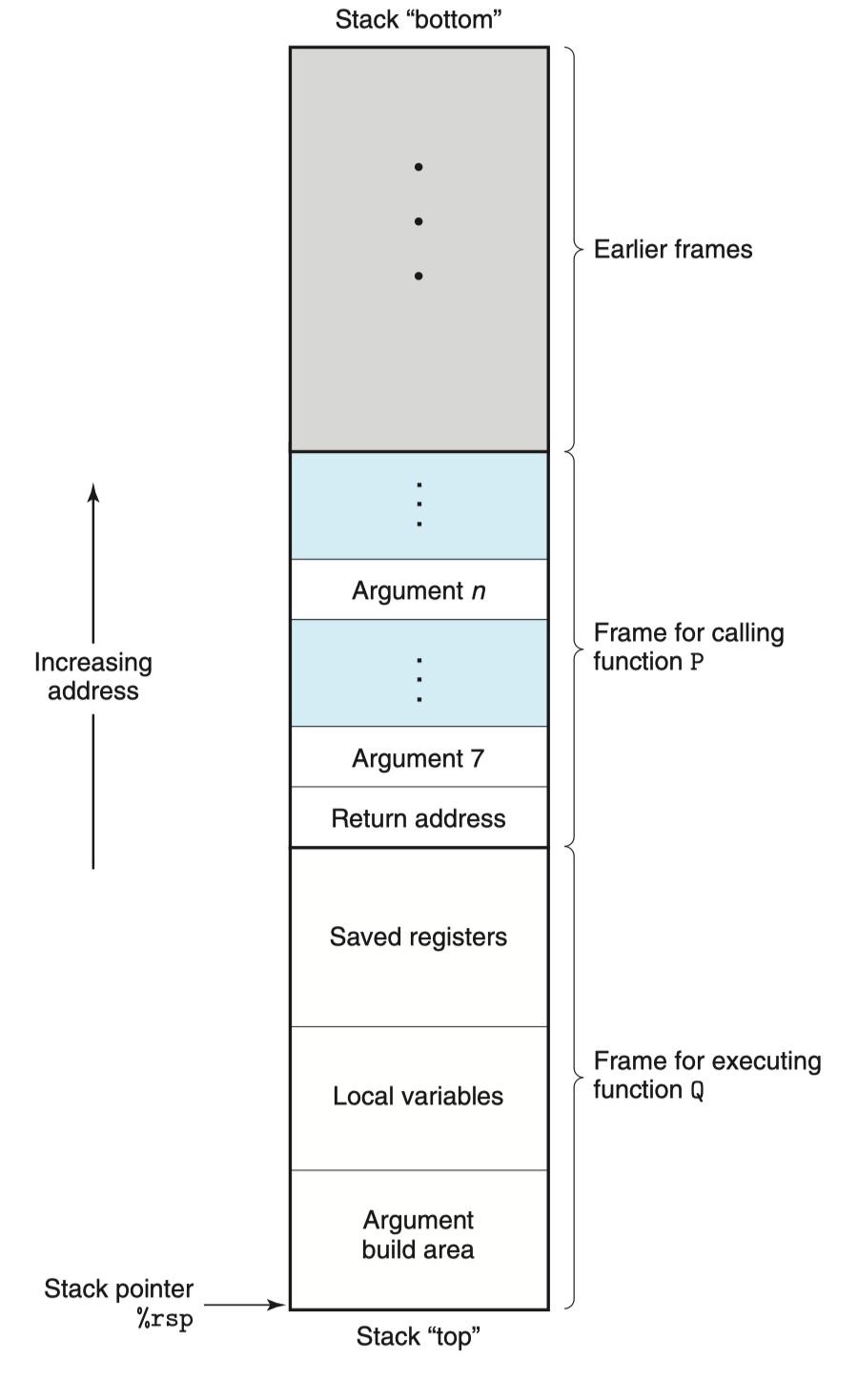
函数调用经常是嵌套的,在同一时刻,堆栈中会有多个函数的信息。每个未完成运行的函数占用一个独立的连续区域,称作栈帧(Stack Frame)。栈帧是堆栈的逻辑片段,当调用函数时逻辑栈帧被压入堆栈, 当函数返回时逻辑栈帧被从堆栈中弹出。
栈帧存放着函数参数,局部变量及恢复前一栈帧所需要的数据等。在 x86-64 中,函数所需的存储空间超出寄存器能够存放的大小时,才会在栈上分配空间。
接着,我将根据栈帧和整数寄存器两个图,介绍过程的三个特性。
① 如何实现传递控制?¶
将控制从函数 P 转移到函数 Q 只需简单地把程序计数器 PC 设置为 Q 的代码的起始位置。
为了成功从 Q 返回到 P,可以看到,P 的栈帧的栈底是返回地址,该地址指明了当 Q 返回时,将要从 P 程序的哪个位置继续执行(通常是调用 Q 的指令的下一句)。
此时,当 Q 执行完毕,Q 的栈帧将被全部弹出,再次调用 popq 指令,即可获取返回地址。
那么,上述功能是如何通过指令实现的呢?

在 x86-64 机器中,当 P 调用 Q 时,其指令为:
该指令首先修改程序计数器寄存器 %rip 的值为被调函数 Q 的地址(0x400540),随后将返回地址压入栈中,也就是将下一句的地址压入栈中,此时开始 Q 的执行。
本例中,将地址 0x400568 压入栈中,如图(b)所示:
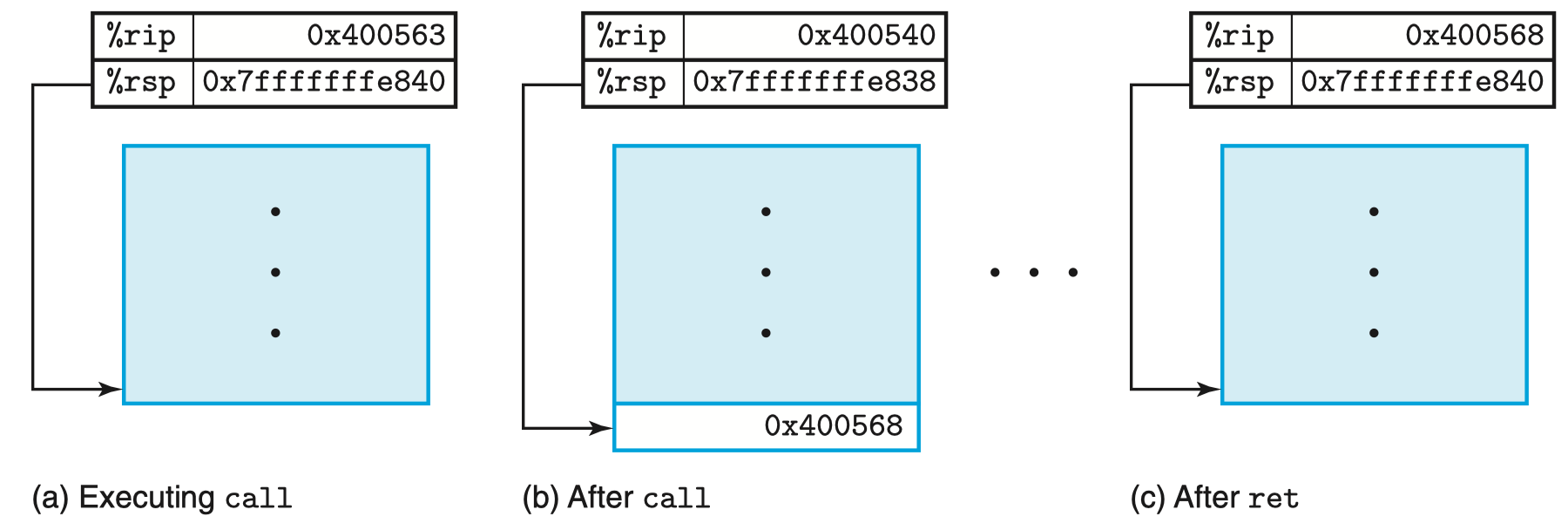
接着进入过程 Q 的执行,当 Q 执行完毕时,其最后一句指令为:
该指令从栈中弹出返回地址(0x400568),并将程序计数器寄存器 %rip 的值修改为该值,成功返回到函数 P。也就是说 ret 相当于:
但是在此之前,还需要一点操作,那就是当过程 Q 执行完毕的时候,栈中如图所示:

观察到当前栈顶 %rsp 仍然 指向函数 Q 的帧栈,想要拿出 return address,需要将 Q 的栈帧全部弹出。
那么,如何弹出被调函数 Q 的栈帧呢?(CSAPP 203)
通常来说,在函数 Q 的开头,会有一句:
由于此时处在函数 Q 的开头,且%rsp 指向栈顶,但对于函数 Q 的栈帧而言,函数 Q 还没开始,因此函数 Q 的栈帧也还没开始分配,因此 %rsp 此时指向函数 Q 栈帧的起始位置,因此将其保存到 %rbp 中。
注意,在此之前,通过 push %rbp 存储的是函数 P 的栈帧起始位置,由于已经将 %rbp 保存,而且此时在操作函数
Q,因此通过 mov %rsp, %rbp 将函数 Q 的栈帧起始位置保存到 %rbp 中。
当函数 Q 结束时,会有一句:
leave 指令相当于:
需要意识到,此时我们在操作函数 Q,而 %rbp 中存储了函数 Q 的栈帧起始位置,而当前函数 Q 执行完毕了,因此要将函数 Q
的栈帧删除,故而执行 mov %rbp, %rsp。
在执行 mov %rbp, %rsp 之前:

执行后成功将函数 Q 的栈帧删除,随后执行 pop %rbp,将之前保存的 函数 P 的 %rbp 的值 写入到寄存器 %rbp 中。
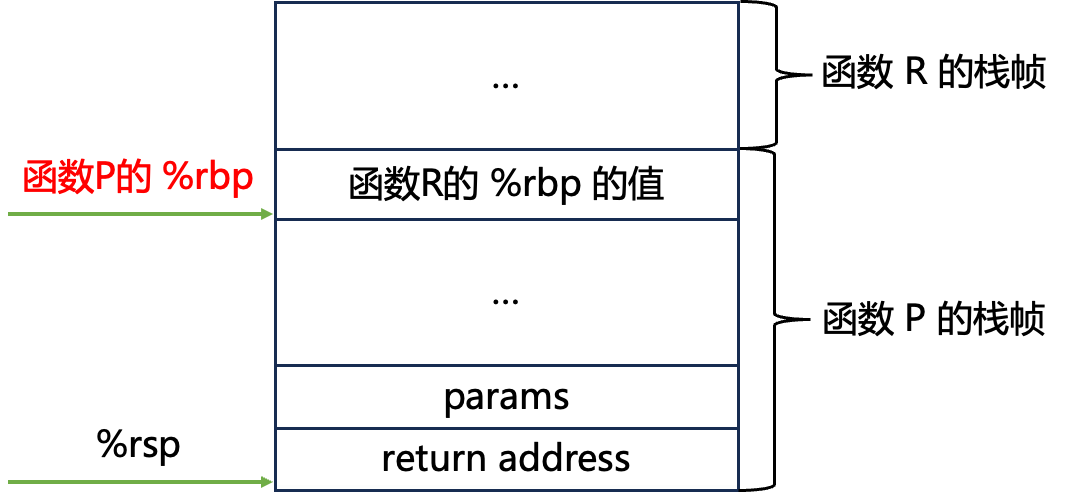
在上面栈帧的分布中讲过,调用函数 P 将:
- 被调函数 Q 所需的参数
- 返回值(call 指令的下一句语句的地址)
保存到函数 P 的栈帧中,接着就开始被调函数 Q 的栈帧,该栈帧中首先保存 被调者保存寄存器,其中包含 %rbp,该寄存器中存储了栈帧起始地址。
此时,再执行 ret 指令时,就可以成功 pop %rip ,从函数 Q 返回到函数 P。
当然,若函数 R 调用了函数 P,同样的原理可以返回!
总结一下,函数的起始指令通常如下:
② 如何实现数据(参数和返回值)传递?¶
x86-64 中,通过 寄存器 %rax 存储返回值。
通过寄存器可传递最多 6 个整形(整数和指针)参数,按参数顺序从左到右依次被如下寄存器保存:%rdi, %rsi, %rdx, %rcs, %r8, %r9
当函数有大于 6 个整形参数,超过 6 个的参数会被放到栈上,首先压入参数 n,其次压入参数 n-1,直至压入参数 7,如上述栈帧图所示,当压入所有参数后,将会压入 Q 的返回地址。
void proc(long a1, long *a1p, int a2, int *a2p, short a3, short *a3p, char a4, char *a4p) {
...
}
void call_proc(){
proc(...);
return;
}
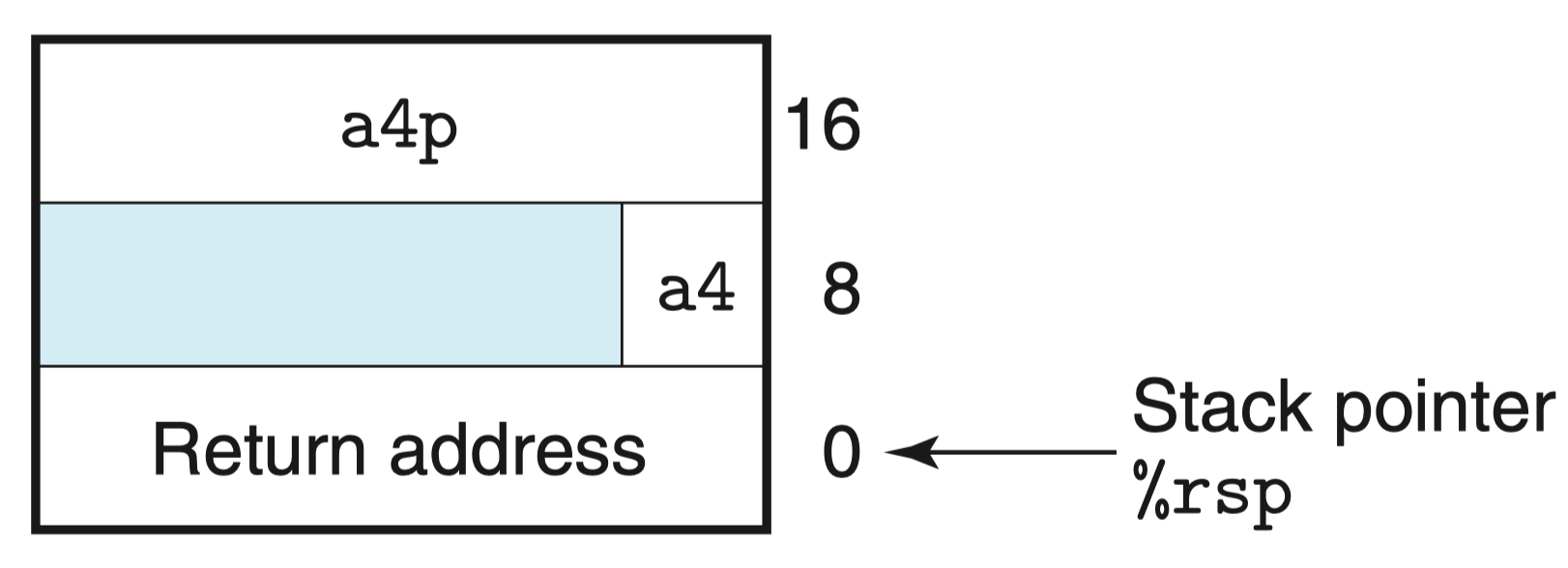
上述函数有 8 个参数,包括字节数不同的整数(8,4,2,1)和不同类型的指针(指针均为 8 字节)。
当 call_proc 函数调用 proc 函数时,前 6 个参数将通过寄存器传递,例如参数 1(a1)将被存入寄存器 %rdi,参数 2(*a1p)将被存入寄存器 %rsi,依次类推。
随后将会先压入参数 n,此处为参数 8(*a4p),最后压入参数 7(a4),此时函数 call_proc 的栈帧结构如图所示:
③ 如何实现分配和释放内存(栈)?¶
目前为止的大部分是案例都可以将数据存储在寄存器中,但有些时候,局部数据必须存放在内存中:
- 寄存器不足够存放所有本地数据
- 对一个局部变量使用地址运算符 &,因此必须能够为它产生一个 地址
- 某些局部变量是数组或结构,因此必须能够通过数组或结构引用被访问到(本质上也是 & 导致的地址问题)
long call_proc() {
long x1 = 1;
int x2 = 2;
short x3 = 3;
char x4 = 4;
proc(x1, &x1, x2, &x2, x3, &x3, x4, &x4);
return (x1+x2)*(x3-x4);
}
此处将对前文的知识进行融汇贯通,call_proc 是一个必须在栈上分配存储空间的函数,因为它对局部变量使用了 & 操作。
此外,call_proc 还需要向具有 8 个参数的函数 proc 传递值,细心地读者会发现,此处的例子是对上例的完整补充。
上述代码生成的汇编代码如图所示:
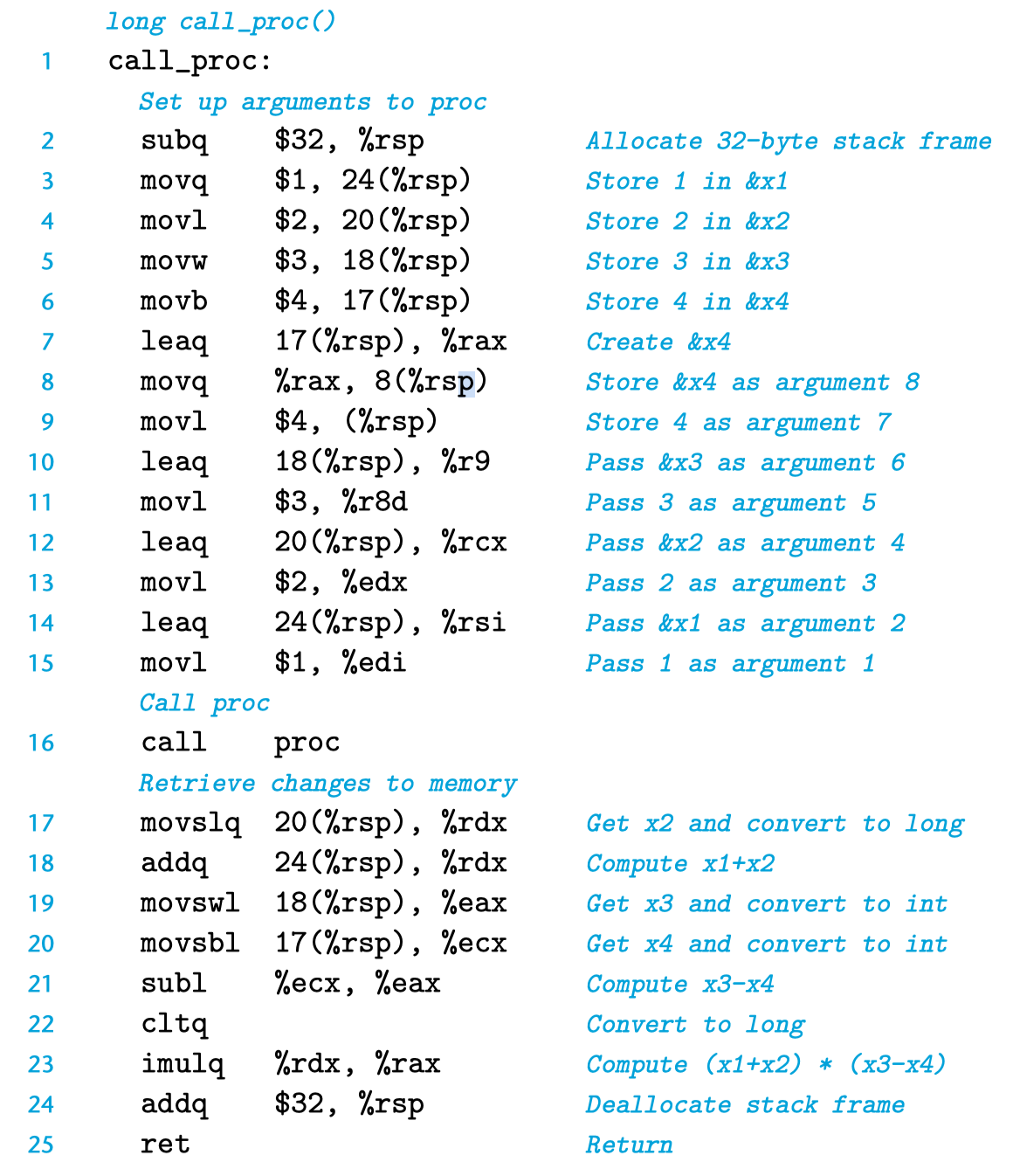
首先,由于 4 个局部变量均需要存储到栈上,在汇编代码的第 2 行,将 %rsp 的值减少 32,其含义为为该函数分配了 32 字节的空间:
-
局部变量(local variables):在第 3 行,其含义是将 $1 写入 %rsp + 24 的位置,后续语句依次类推。
-
参数构造区(argument build area):在第 8 和 9 行,将参数 8 和 7 压入栈中,其余 6 个参数写入栈中。
注意:由于此处参数均为整数、指针,因此可以写入整型寄存器
此时,已经完成了内存的分配,下图为函数 call_proc 此时的栈帧(该图为上一幅栈帧图的补充版):
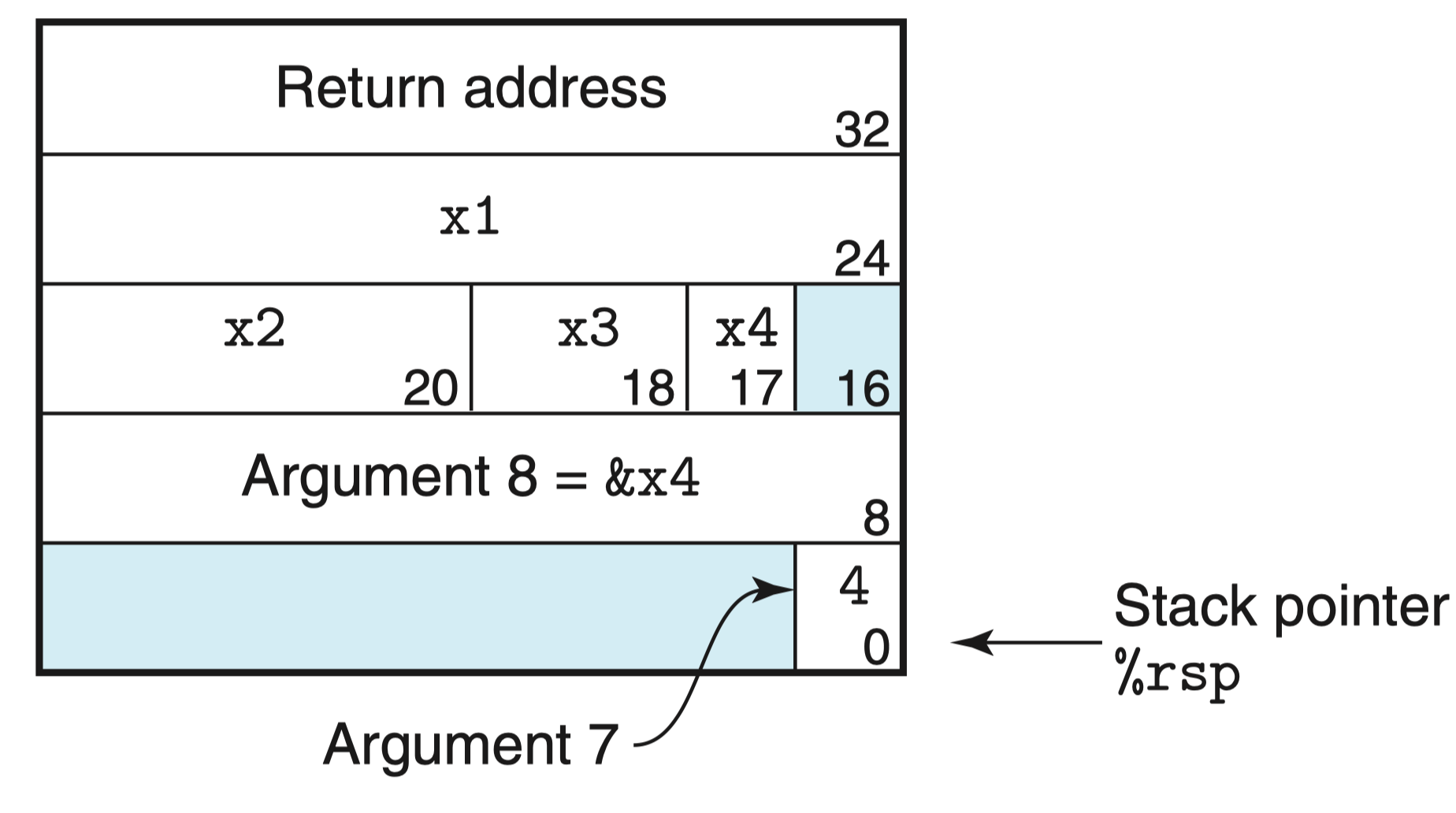
接着在 16 行执行 proc 函数的调用:
该指令调用该函数时,会将程序计数器 %rip 修改为 proc 程序的起始地址,并将 call proc 的下一句的地址压入栈帧中,作为返回地址(此处并未画出)。
注意:此处图中的 Return address 是调用 call_proc 的函数的返回地址,而不是我们压入的返回地址!
接着,proc 函数执行完后,其最后一个语句是 ret,此时返回到 call_proc 的第 17 行,接着第 17~23 行在执行 (x1+x2)*(x3-x4);
第 24 行将 %rsp 的值增加 32,其含义为删除分配的栈内存,此时 %rsp 指向图中的 Return address
第 25 行的 ret 表示 call_proc 执行完毕,ret 会从栈中弹出 Return address,该地址为调用 call_proc 的函数的返回地址。
寄存器中的局部存储空间
此时,我们已经介绍了上述整型寄存器图中的绝大部分,包括:
- %rsp:栈顶指针寄存器
- %rax:保存函数的返回值
- %rdi, %rsi, %rdx, %rcs, %r8, %r9:但函数 P 调用函数 Q 时,假设 Q 有 n>6 个参数,前 6 个参数的值会按顺序依次存储到上述寄存器中
此外,还介绍了程序计数器寄存器:%eip
还有 8 个整型计数器未被介绍:
- 被调用者保存寄存器:%rbx, %rbp, %r12, %r13, %r14, %r15
%rbp:栈帧指针,用于标识当前栈帧的起始位置。
当函数 P 调用函数 Q,Q 作为被调用者必须保证在 Q 返回到 P 时,上述寄存器的值不变。也就是说,Q 要么根本不去更改它,要么就是把原始的值压入栈中,改变寄存器的值,然后在返回前从栈中弹出旧值。
此处压入栈的值会在栈帧中穿件标号为“被保存的寄存器“的一部分。
- 所有其他的寄存器,除了栈指针 %rsp,均为 调用者保存寄存器,包含未提及的 %r10 和 %r11。顾名思义,当 P 调用 Q,Q 可以任意修改,因为在调用之前首先保存好这些寄存器的值是 P(调用者)的责任。
那么,P 如何保存呢?
上述代码中的值 u 和 v 需要被保存,因为将用于 u + v 的计算,P 可以通过将 u 和 v 的值先写入被调用者保存寄存器中,例如在调用 Q(x) 之前,需要将 u 的值写入 %rbx 中,此时 Q 需要保证 %rbx 的值不变,成功完成保存。
数据对齐¶
许多计算机系统对基础数据类型的合法地址做了限制,要求某种类型对象的地址必须是某个值 K 的倍数,可以提高性能。
对齐原则为任何 K 字节的基本对象的地址必须是 K 的倍数:
- char:1 字节
- short:2 字节
- int,float:4 字节
- long,double,char*:8 字节
其有两种可能的内存分配方式:
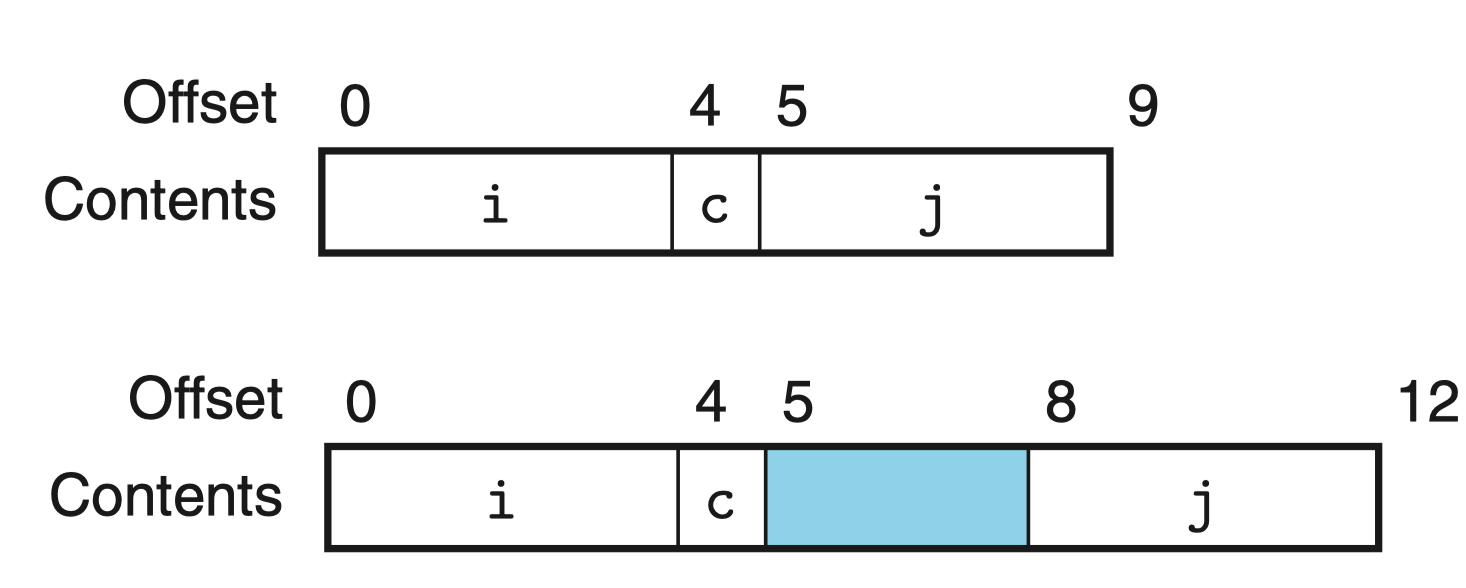
前者是最小分配,并未进行数据对齐。由于 j 为 int 类型,为 4 字节,此时他的地址也必须是 4 的倍数,此处地址为 5 显然不满足。
于是需要插入 3 个空白字节的间隙(蓝色),此时就满足了要求!
有时候虽然每个元素都满足对齐要求,仍然需要在结构体的末尾添加空白元素:

内存越界引用和缓冲区溢出¶
C 对于数组引用不进行任何边界检查,而且局部变量和状态信息(例如保存的寄存器值和返回地址)都存放在栈中。当两种情况结合到一起时,会导致严重的程序错误,对越界的数组元素的写操作会破坏存储在栈中的状态信息。
使用 gets 函数从标准输入读入一行,通过 puts 输出。注意读入的数据可能大于 buf 的长度,因为 gets 无法确定是否为保存整个字符串分配了足够的空间。
由于我们只给 buf 分配了 8 字节长度,因此仍任何超过 7 字节的字符串都会导致写越界。
C 语言的字符串末尾是 '\0',占用 1 个字节。
汇编代码见 CSAPP 195,其对应的栈帧如图所示:
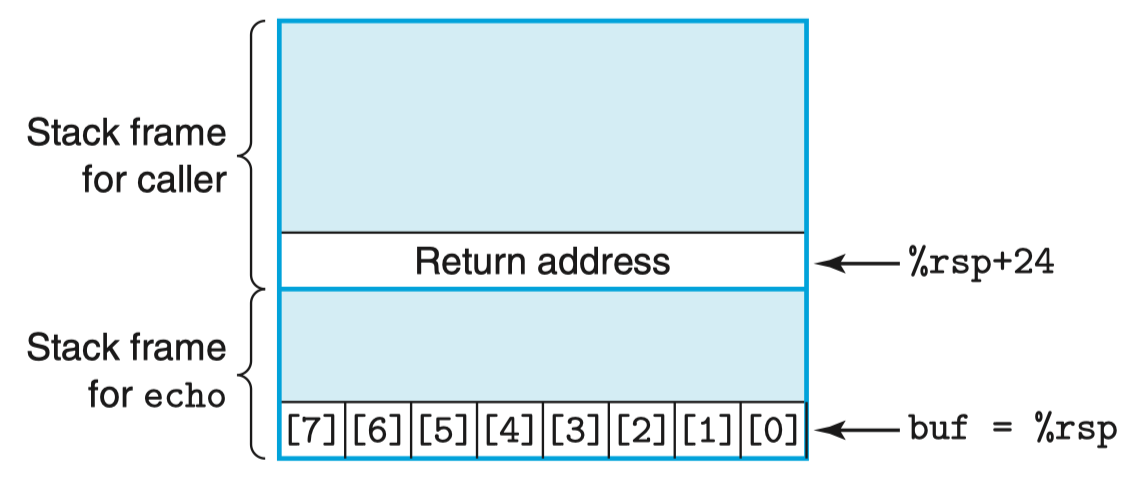
字符串长度为 0 ~ 23 字节时后果并不严重,但超过以后,返回指针的值将会被破坏,此时 ret 指令会导致程序跳转到一个意想不到的位置。
缓冲区溢出更加致命的使用就是让程序执行恶意代码。下面将介绍几种对抗缓冲区溢出攻击的方法:
- 地址空间布局随机化(ASLR)
- 栈破坏检测(canary)
- 限制可执行代码区域(NX)
此外 PIE 技术很容易与 ASLR 混淆,也会同时介绍!
①ASLR 与 PIE¶
ASLR
为了在系统中插入攻击代码,攻击者既要插入代码,也要插入指向这段代码的指针,这个指针也是攻击字符串的一部分,产生这个指针 需要知道字符串放置的栈地址。
而栈随机化的思想,可以使栈的位置在程序每次运行时都有变化,其实现的方式是在程序开始时,在栈上分配一段空间,但并不使用,该空间会导致程序每次执行时后续的栈位置都发生变化。
在 32 位 Linux 上运行该程序 n 次,其地址变化范围为 0xff7fc59c ~ 0xffffd09c,约 \(2^{23}\),在 64 位上范围大小约 \(2^{64}\)。
栈随机化属于地址空间布局随机化(ASLR)中的一种,采用 ASLR,每次运行时程序的不同部分,包括程序代码、库代码、栈、全局变量和堆数据,都会被加载到内存的不同区域。
简单来说,当程序被加载到内存中时,或者说,每个程序的虚拟内存分部是固定的,从低到高地址依次是:代码、堆和栈,而 ASLR 正是对这三者的地址进行随机。
通常 ASLR 有 0/½ 三种级别,其中 0 表示 ASLR 未开启,1 表示随机化 stack、libraries,2 还会随机化 heap。
配置 ASLR 级别:
修改该文件的值(0/½)即可对 ASLR 级别进行配置,默认为 2.
常用破解方法
攻击者可以在实际的攻击代码前插入很长一段的 nop 指令,该指令的作用是对程序计数器加 1,使其指向下一条指令,没有任何其他效果,只要攻击者能猜中这段序列中的某个 nop 指令的地址,那么程序就会经过这个 nop 指令序列,到达攻击代码。
这个序列的常用术语是 “空操作雪橇(nop sled)”,意思是程序会 “滑过” 这个序列。
若我们建立 \(2^8\) 字节的 nop sled,那么枚举 \(2^{23-8} = 2^{15}=32768\) 个起始地址就能破解 32 位 Linux 的随机化,但想枚举破解 64 位系统还是难度很大。
PIE
ASRL 是系统级别的技术,作用于程序(ELF)装入内存运行时;而 PIE 是编译器(gcc)提供的功能,作用于程序(ELF)编译生成时。
由于 ASLR 是一种操作系统层面的技术,而二进制程序本身是不支持随机化加载的,便出现了一些绕过方式,例如 ret2plt,GOT 劫持,地址爆破等。
于是,人们于 2003 年引入了位置无关可执行文件(Position - Independent Executable,PIE),其在应用层的编译器上实现,通过将程序编译为位置无关代码(Position - Independent Code,PIC),使程序可以被加载到任意位置, 就像是一个特殊的共享库。
使用命令 gcc -v 查看 gcc 默认的开关情况。如果含有 --enable-default-pie 参数则代表 PIE 默认已开启,此时编译出来的 ELF
用 file 命令查看会显示其为 so,其随机化了 ELF 装载内存的基址(代码段、plt、got、data 等共同的基址)。
若想关闭 PIE 则需要在编译指令中添加参数 -no-pie。
在 PIE 和 ASLR 同时开启的情况下,攻击者将对程序的内存布局一无所知,上述绕过方式均失效,大大增加了利用难度。
当然,凡事有利也有弊,在增加安全性的同时,PIE 也会一定程度上影响性能,因此绝大多数操作系统上 PIE 仅用于对一些安全性要求较高的程序。
注意,PIE 必须 在 ASLR 至少为 1 的情况下才会生效,若为 0 级,不会生效。
为什么呢,因为 PIE 是能力赋予,ASLR 是真正使用能力。
而且在开启 PIE 的情况下,即便 ASLR 为 1,对 heap 的随机化也会生效,因为改变了基址。
具体实验推荐查看:关于 Linux 下 ASLR 与 PIE 的一些理解
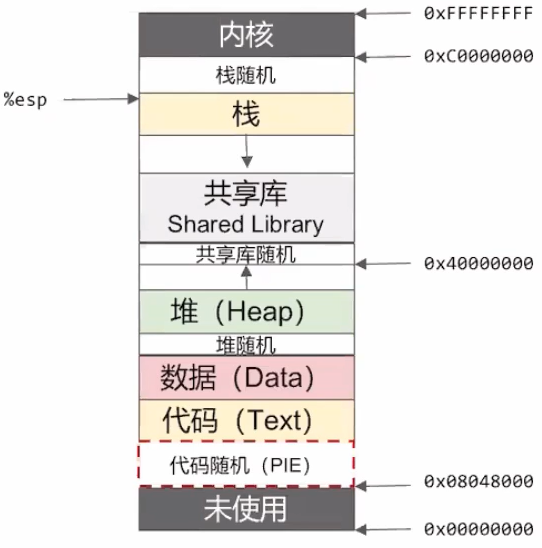
32 位下,同时开启 ASLR 与 PIE 如下图所示。可以看到 PIE 的作用是使代码和数据的字节随机,同时也会自然影响到堆地址(ASLR = 2)
②canary¶
计算机的第二道防线是能够检测到何时栈已经被破坏。上文提到,破坏通常发生在超越局部缓冲区的边界时。GCC 在最近的版本中加入了 栈保护者(stack protector) 机制,用于检测对缓冲区越界的读写。
栈破坏检测的思想是在栈帧中任何局部缓冲区与栈状态之间存储一个特殊的 金丝雀值(canary) 也称为 哨兵值(guard value)。
canary 是在程序每次运行时随机产生的,因此攻击者没有简单的方法获取其具体值,其被存放在一个特殊的 只读段 中,如此,攻击者也无法覆写 canary 值。
在恢复寄存器状态和从函数返回之前,程序检查 canary 是否被该函数的某个操作或者该函数调用的某个函数的某个操作改变了,若 发现canary 被篡改,则程序将异常终止。
通过命令行选项 -fno-stack-protector 可以阻止 GCC 产生 cannary 保护代码,否则将默认生成。
术语“金丝雀”源于历史上用这种鸟在煤矿中察觉有毒的气体

如图所示,若 buf 溢出,则栈中保存的 Canary 处的值和真正的在特殊只读段中的 Canary 的真值将不相同,当函数执行完毕返回之前,检测栈上的 Canary 发现被篡改,则认为例如 %ebp 等保存的寄存器信息、Return address 也被篡改,程序将异常终止!
③NX(DEP)¶
第三道防线是消除攻击者向系统中插入可执行代码的能力。如何消除呢?
一种方法是限制那些内存区域能够存放可执行代码。在典型的系统中,只有保存编译器产生的代码的内存区域才需要是可执行的,其他区域均可以被限制为只允许读写,而不允许执行。
根据虚拟内存的知识,虚拟内存空间在逻辑上被分成了页,典型的每页 2048 或 4096 字节,硬件支持多种形式的内存保护,能够指明用户程序和系统内核所允许的访问模式,通常分为三种访问模式:
- 读(从内存读数据)
- 写(存储数据到内存)
- 执行(将内存的内容看做是机器级代码)
以前,X86 体系将读和执行访问控制合并为同一个 1 位的标志,即可读的页必定可执行,而栈必须是可读写的,因此栈上的字节也必须是可执行的。虽然有很多其他机制可以限制某些页可读但不可写,但都会带来严重的性能损失。
然后最近 AMD 为 64 位处理器的内存保护引入了 NX(No-Execute)位,将读和执行访问模式区分开来,而 Inter 也随后跟进。
至此,栈可以被标记为可读和可写,但不可执行,由于检查页是否可执行由硬件完成,没有性能损失。
- 可写、不可执行:栈、堆、数据
- 不可写、可执行:只读数据、代码
GCC 默认启用 NX 选项,通过添加 -z execstack 关闭 NX。
在 Linux 下称为 NX,在 Windows 下称为 DEP。
目前来说,一旦开启 NX,则可写与可执行不可兼得,由此起到保护作用!
处理器体系结构¶
根据上一章《程序的机器级表示》,我们知道处理器必须执行一系列指令,每条指令执行某个简单操作,例如两个数相加(指令 addq)。
所谓 指令是被编码为由一个或多个字节序列组成的二进制格式,例如:
二进制序列 0x488b542408 通过反汇编即可获得其对应的指令 move 0x8(%rsp), %rdx
一个处理器支持的指令和指令的字节级编码称为它的 指令集体系结构(ISA),不同的处理器家族(例如 Intel IA32、x86-64、AMD)都有不同的 ISA,这意味 着一个程序编译成可以在某一种机器上运行,就不能在另一种机器上运行。
本章主要介绍硬件系统如何执行 ISA 指令,一个重要的概念是:现代处理器实际的工作方式可能跟 ISA 隐含的计算模型大相径庭。
ISA 模型看上去应该是 顺序指令执行,即先取出一条指令,等待它执行完毕,再执行下一条。
然而,与同一时刻只执行一条指令相比,通过同时处理多条指令的不同部分,处理器可以获得更高的性能。为了保证处理器能得到同顺序执行相同的结果,需要一种特殊的机制来实现。
RISC 和 CISC 指令集:
- CISC:复杂指令集计算机,例如 x86-64
- RISC:精简指令集计算机,例如 ARM
假设向设计一个处理器,主要分为如下步骤:
- 指令及其编码
- 异常处理
- 电路、硬件(todo):大多数现代电路设计都是用信号线上的高电压和低电压来表示不同的位值。
① 指令及编码:Y86-64
将设计的 ISA 命名为 Y86-64,因为受到 x86 的启发!
具体可查看 CSAPP P246。
举个例子:ret 指令的 16 进制为 90。
该 ISA 共设置 15 个寄存器,每个寄存器都有一个相对应的范围在 0 到 0xE 之间的 寄存器标识符(register ID),该寄存器编号与 x86-64 中的相同。
这种寄存器称为程序寄存器,存在 CPU 中的一个寄存器文件,该寄存器文件就是一个以寄存器 ID 作为地址的随机访问存储器。
举个例子:
-
rmmovq 的字节为 40
-
%rsp 的地址为 4
-
%rdx 的地址为 2
-
0x123456789abcd 首先填充 0 使其变为 8 字节: 00 01 23 45 67 89 ab cd
-
由于所有整数采用小端序编码,当指令按照反汇编格式书写时,字节会以相反的顺序出现
因此将字节返序,得到 cd ab 89 67 45 23 01 11
于是得到指令的最终编码:
② 异常处理
参考《异常控制流:中断与系统调用》
③TODO
随后书本介绍了顺序和流水线两种形式的实现,此处介绍一下指令执行的顺序:
-
取值:PC 记录了下一个待执行指令的地址,基于该地址从内存中读取指令字节
-
译码:按照预定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类别以及各种获取操作数的方法。 该阶段还负责从寄存器中读出值。
-
执行:完成指令所规定的各种操作,具体实现指令的功能。为此,CPU 的不同部分被连接起来,以执行所需的操作。
例如,如果要求完成一个加法运算,算术逻辑单元 ALU 将被连接到一组输入和一组输出,输入端提供需要相加的数值,输出端将含有最后的运算结果。
-
访存:将数据写入内存,或从内存中读取数据
-
写回:通常是将数据写入寄存器中
-
更新 PC:将 PC 设置为下一条指令的地址
存储器层次结构¶
在上文的研究中,我们依赖于一个简单的计算机系统模型:CPU 执行指令,而存储器系统为 CPU 存放指令和数据,将其认为是一个线性的字节数组,而 CPU 能够在一个常数时间内访问每个存储器位置。
但实际上,现代存储器系统是一个具有不同容量、成本和访问时间的存储设备的层次结构:
- CPU 寄存器
- 高速缓存存储器:靠近 CPU、容量小且快速。缓存存储在相对慢速的主存储器中数据和指令的一部分。
- 主存储器(主存):缓存存储在容量大且慢速的磁盘上的数据
- 磁盘:持久存储,上述几种断电后数据消失。
层次机构之所以可行,是因为局部性原理,通常会频繁的访问局部数据。
几个名词:
- 静态 RAM(SRAM):快、贵、不可持久存储
- 动态 RAM(DRAM):没 SRAM 快,但相对便宜,不可持久存储
- 可擦写可编程 ROM(EPROM),可持久存储
- 闪存是一种非易失性存储器,基于 EEPROM(类似 EPROM),而固态硬盘(SSD)正是新型的基于闪存的磁盘驱动器
- 磁盘:可持久存储,很慢,详见 CSAPP 407
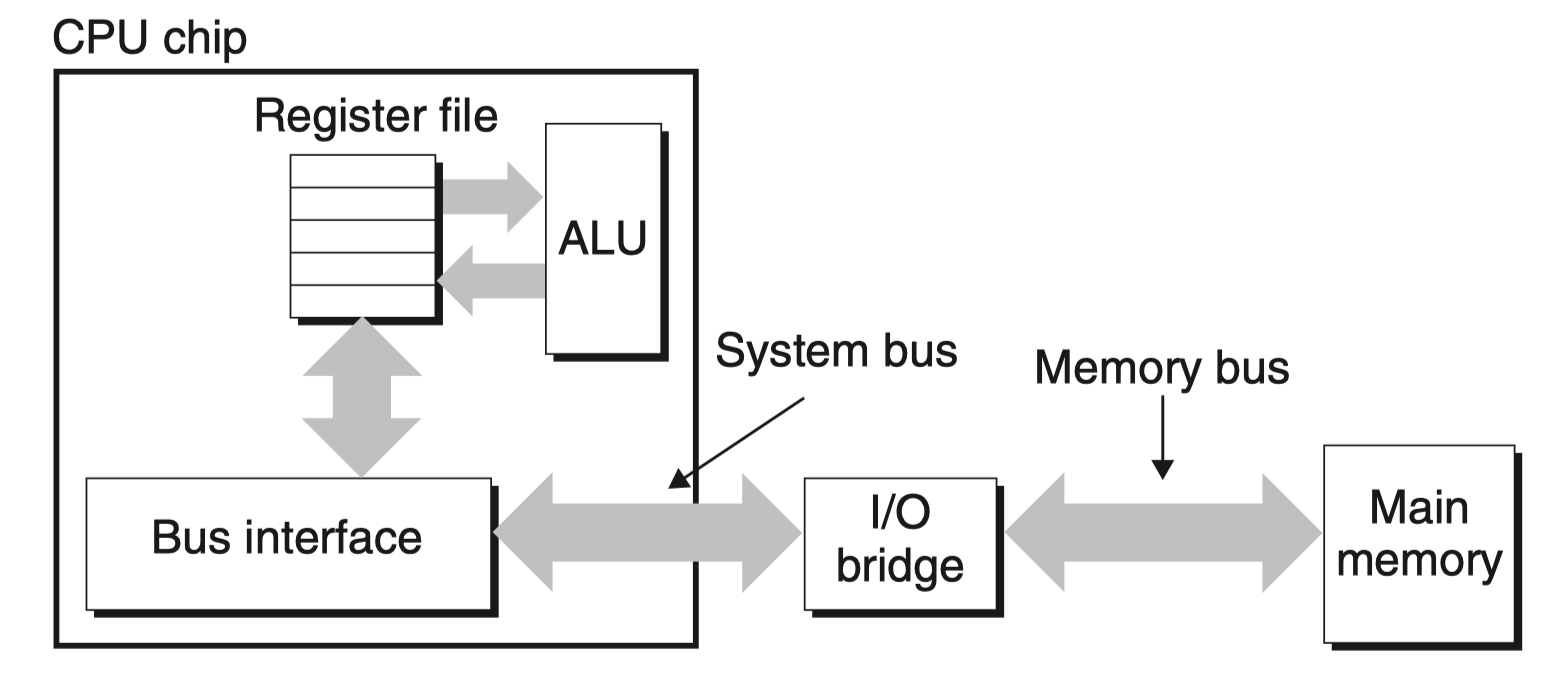
DRAM 有多种改良增强版本,现代的 主存 通常就是使用 DRAM,那如何访问主存呢?
数据流通过成为 总线(bus) 的共享电子电路在处理器和 DRAM 主存之间来来回回,详细读取参见 CSAPP 406
异常控制流¶
结合程序的机器级表示和处理器体系结构两章可知,寄存器 PC 中存放了待执行指令 \(I_k\) 的地址,CPU 会根据 PC 中的地址从内存中获取指令。
通常来说,从指令 \(I_k\) 到 \(I_{k+1}\) 的转变是平滑的,也就是\(I_k\) 和 \(I_{k+1}\)在内存中的位置是相邻的。
但偶尔也会发生 控制流突变,例如跳转、调用和返回这样一些程序指令,这块内容在程序的机器级表示中进行了介绍。例如当发生函数调用时,call 指令会修改 PC 至目标位置,并将返回地值压入栈中,被调函数执行完毕后,最后一句 ret 指令会将返回地址从栈中弹出。一般返回地址就是 call 指令的下一句指令所在的地址。此外,还有 jmp 等跳转指令也会产生位置突变。
上述机制使得程序能够对程序变量表示的内部程序状态中的变化做出反应
但是,系统也必须能够对系统状态的变化做出反应,这些系统状态不是被内部程序变量捕获的,也不一定要和程序的执行相关。例如:
- 一个硬件定时器定期产生信号,这个时间必须得到处理。
- 包到达网络适配器后,必须存放在内存中。
- 程序向磁盘请求数据,然后休眠,直到被通知说数据已就绪。
- 当子进程终止时,创建它的父进程必须得到通知。
现代系统通过使控制流发生突变来对这些情况做出反应,我们将此类突变称为 异常控制流。
异常控制流发生在计算机系统的各个层次,例如:
- 在硬件层:硬件检测到的事件会触发控制突然转移到异常处理程序
- 在操作系统层:内核通过上下文切换将控制从一个用户进程转移到另一个用户进程
- 在应用层:一个进程可以发送信号到另一个进程,而接受者会将控制突然转移到它的一个信号处理程序。
总的来说,一个程序可以通过回避通常的栈规则,并执行到其他函数中任意位置的非本地跳转来对错误做出反应。
本章将根据异常发生的三个层次介绍。
硬件层:异常¶
异常(exception)是异常控制流的一种形式,它的一部分由硬件实现,一部分由操作系统实现。
简单来说,异常就是控制流中的突变,用来 响应处理器状态中的某些变化。
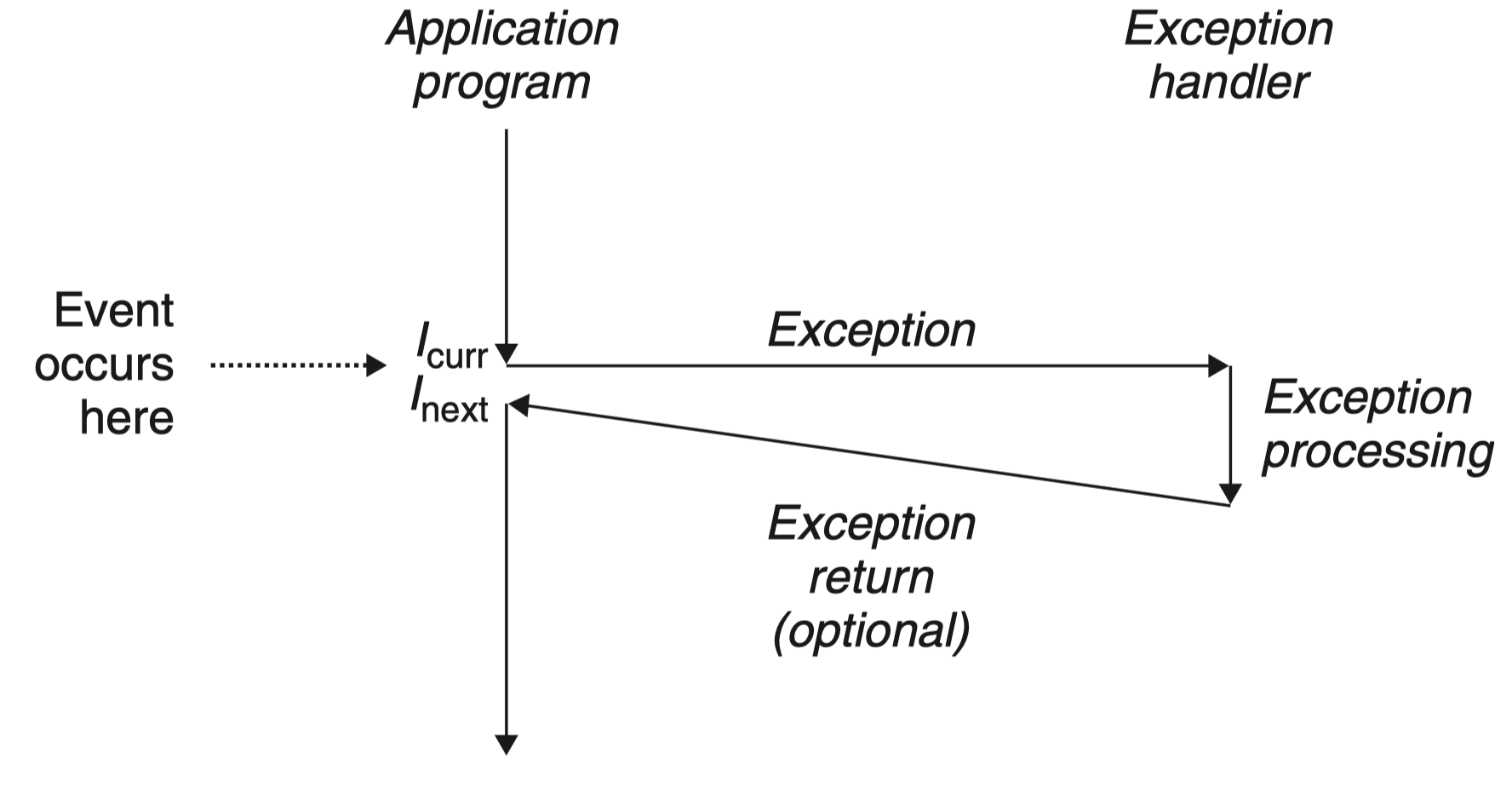
在图中,当处理器状态中发生一个重要的变化时,处理器正在执行某个当前指令 \(I_{curr}\)。在处理器中,状态被编码为不同的位和信号。状态变化称为 事件(event):
- 事件可能和当前指令的执行直接相关。比如,发生虚拟内存缺页、算术溢出,或者一条指令试图除以零。
- 事件也可能和当前指令的执行没有关系。比如,一个系统定时器产生信号或者一个 I/O 请求完成。
在任何情况下,当处理器检测到有事件发生时,它就会通过一张叫做 异常表(exception table)的跳转表,进行一个间接过程调用(异常),到一个专门设计用来处理这类事件的操作系统子程序,称为 异常处理程序(exception handler).
当异常处理程序完成处理后,根据引起异常的事件的类型,会发生以下 3 种情况中的一种:
- 处理程序将控制返回给当前指令 \(I_{curr}\) ,即当事件发生时正在执行的指令。
- 处理程序将控制返回给 \(I_{next}\) ,如果没有发生异常将会执行的下一条指令。
- 处理程序终止被中断的程序。
前文提到异常由软件和硬件共同实现,此处详细介绍二者的分工。
系统中可能的每种类型的异常都分配了一个唯一的非负整数的 异常号(exception number):
- 一些号码是由处理器的设计者分配:例如包括被零除、缺页、内存访问违例、断点以及算术运算溢出。
- 其他号码是由操作系统内核(操作系统常驻内存的部分)的设计者分配:例如包括系统调用和来自外部 I/O 设备的信号。
在系统启动时(当计算机重启或者加电时),操作系统分配和初始化一张称为 异常表 的跳转表,使得表目 k 包含异常 k 的处理程序的地址,下图展示了异常表的格式:
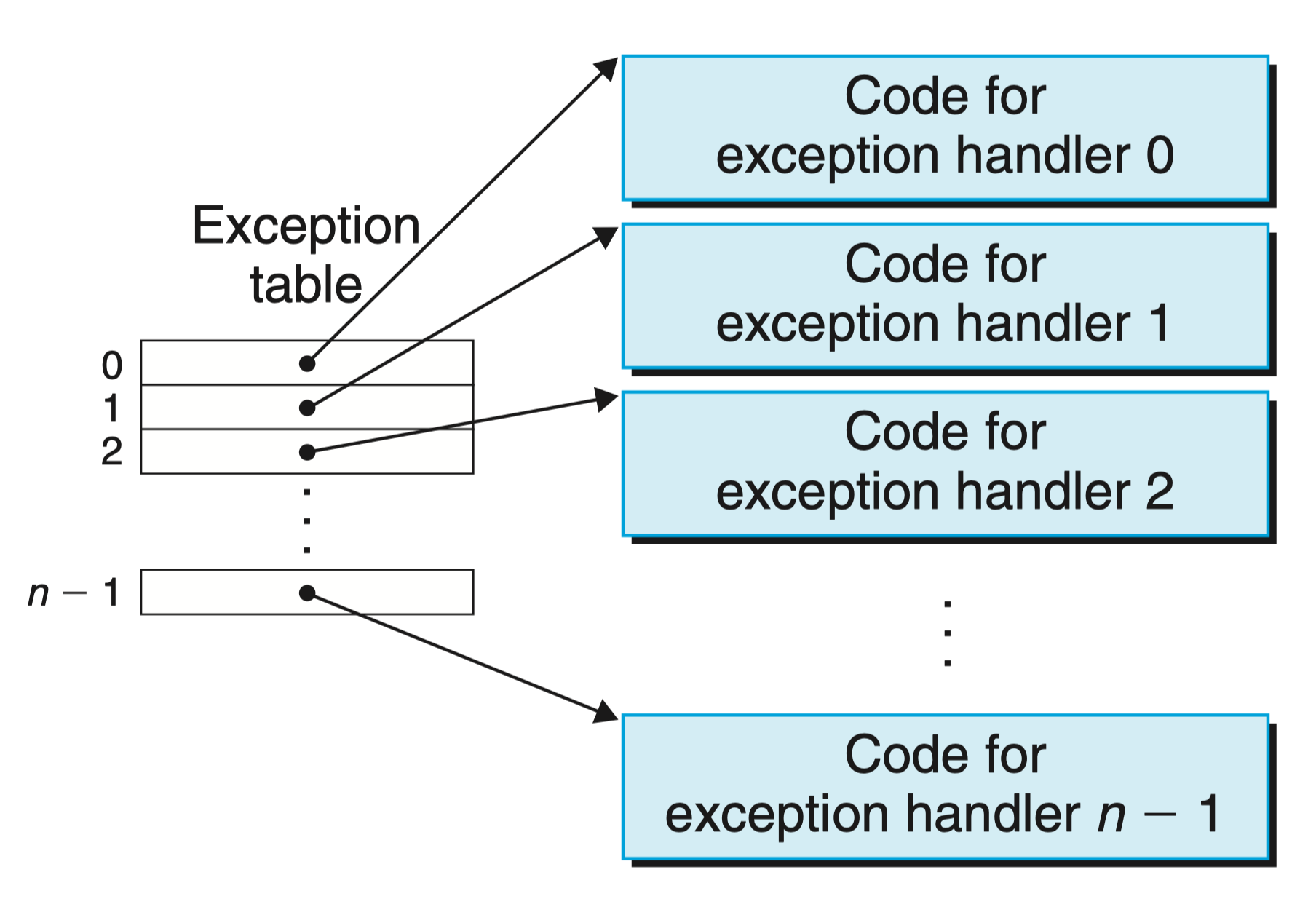
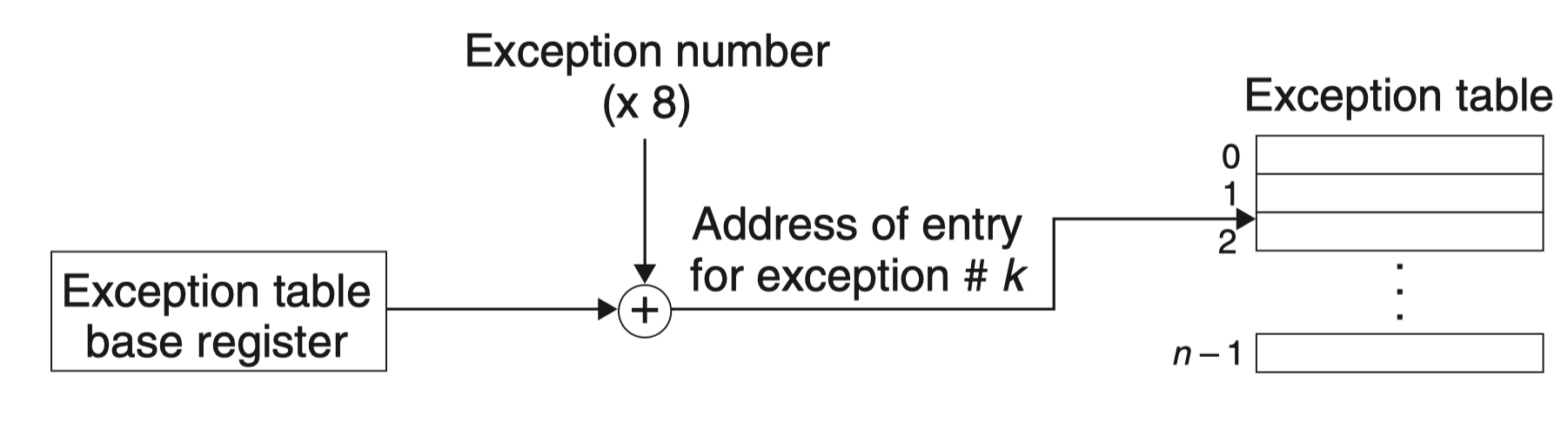
在运行时(当系统在执行某个程序时),处理器检测到发生了一个事件,并且确定了相应的异常号 k。随后,处理器触发异常,方法是执行间接过程调用,通过异常表的表目 k,转到相应的处理程序。下图展示了处理器如何使用异常表来形成适当的异常处理程序的地址。异常号是到异常表中的索引,异常表的起始地址放在一个叫做 异常表基址寄存器(exception table base register)的特殊 CPU 寄存器里。
异常就类似于过程调用(e.g. 函数调用),但也有不同之处,例如如果控制从用户程序转移到内核,所有这些项目都被压到内核栈中,而不是压到用户栈中,此外由于异常处理程序运行在内核模式下,这意味着它们对所有的系统资源都有完全的访问权限。此外,压入栈的内容和返回地址也有所不同。
异常的类别
异常可以分为四类:中断(interrupt),陷阱(trap)、故障(fault)和 终止(abort)。下表对这些类别的属性做了小结。
| 类别 | 原因 | 异步/同步 | 返回行为 |
|---|---|---|---|
| 中断 | 来自 I/O 设备的信号 | 异步 | 总是返回到下一条指令 |
| 陷阱(系统调用) | 有意的异常 | 同步 | 总是返回到下一条指令 |
| 故障 | 潜在可恢复的错误 | 同步 | 可能返回到当前指令 |
| 终止 | 不可恢复的错误 | 同步 | 不会返回 |
对每类异常的详细介绍参考 CSAPP 504
注意到中断是异步发生的,通常是例如网络适配器、定时器芯片等硬件通过像处理器芯片上的一个引脚发信号,并将异常号放到系统总线上来触发中断。
处理中断的异常处理程序被称作 中断处理程序。
接着介绍一下陷阱,陷阱是有意的异常,是执行一条指令的结果。就像中断处理程序一样,陷阱处理程序将控制返回到下一条指令。
陷阱最重要的用途是在用户程序和内核之间提供一个像过程调用一样的接口,叫做系统调用。
用户程序经常需要向内核请求服务,比如读一个文件(read)、创建一个新的进程(fork),加载一个新的程序(execve),或者终止当前进程(exit)。为了允许对这些内核服务的受控的访问,处理器提供了一条特殊的 “syscall n” 指令,当用户程序想要请求服务 n 时,可以执行这条指令。 执行 syscall 指令会导致一个到异常处理程序的陷阱,这个处理程序解析参数,并调用适当的内核程序。
如图概述了一个系统调用的处理:
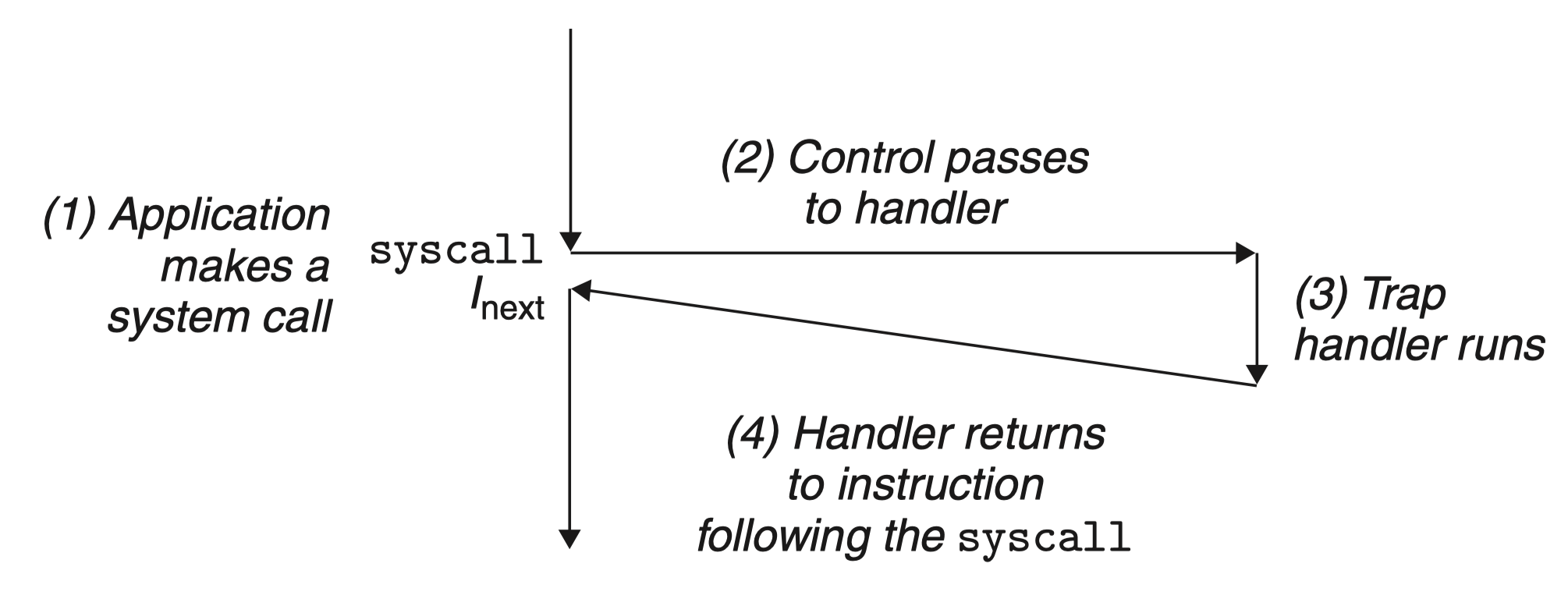
从程序员的角度来看,系统调用和普通的函数调用是一样的。然而,它们的实现非常不同。普通的函数运行在用户模式中,用户模式限制了函数可以执行的指令的类型,而且它们只能访问与调用函数相同的栈。系统调用运行在内核模式中,内核模式允许系统调用执行特权指令,并访问定义在内核中的栈。
Linux/x86-64 系统中的异常
为了使描述更具体,让我们来看看为 x86-64 系统定义的一些异常。有高达 256 种不同的异常类型:
- 0 ∼ 31 的号码对应的是由 Intel 架构师定义的异常,因此对任何 x86-64 系统都是一样的
- 32 ∼ 255 的号码对应的是操作系统定义的中断和陷阱。
| 异常号 | 描述 | 异常类别 |
|---|---|---|
| 0 | 除法错误 | 故障 |
| 13 | 一般保护故障 | 故障 |
| 14 | 缺页 | 故障 |
| 18 | 机器检查 | 终止 |
| 32 ~ 255 | 操作系统定义的异常 | 中断或陷阱 |
① 故障和终止
-
除法错误。 当应用试图除以零时,或者当一个除法指令的结果对于目标操作数来说太大了的时候,就会发生除法错误(异常 0)。Unix 不会试图从除法错误中恢复,而是选择终止程序。Linuxshell 通常会把除法错误报告为“浮点异常(Floating exception)”。
-
一般保护故障。 许多原因都会导致不为人知的一般保护故障(异常 13),通常是因为一个程序引用了一个未定义的虚拟内存区域,或者因为程序试图写一个只读的文本段。Linux 不会尝试恢复这类故障。Linux shell 通常会把这种一般保护故障报告为“段故障(Segmentation fault)”。
-
缺页(异常 14)是会重新执行产生故障的指令的一个异常示例。处理程序将适当的磁盘上虚拟内存的一个页面映射到物理内存的一个页- 面,然后重新执行这条产生故障的指令。我们将在第 9 章中看到缺页是如何工作的细节。
-
机器检查。 机器检查(异常 18)是在导致故障的指令执行中检测到致命的硬件错误时发生的。机器检查处理程序从不返回控制给应用程序。
② 系统调用
Linux 提供几百种系统调用,当应用程序想要请求内核服务时可以使用,包括读文件、写文件或是创建一个新进程。下表给出了一些常见的 Linux 系统调用。每个系统调用都有一个唯一的整数号,对应于一个到内核中跳转表的偏移量。(注意:这个跳转表和异常表不一样。)
| 编号 | 名字 | 描述 | 编号 | 名字 | 描述 |
|---|---|---|---|---|---|
| 0 | read | 读文件 | 33 | pause | 挂起进程直到信号到达 |
| 1 | write | 写文件 | 37 | alarm | 调度告警信号的传送 |
| 2 | open | 打开文件 | 39 | getpid | 获得进程 ID |
| 3 | close | 关闭文件 | 57 | fork | 创建进程 |
| 4 | stat | 获得文件信息 | 59 | execve | 执行一个程序 |
| 9 | mmap | 将内存页映射到文件 | 60 | _exit | 终止进程 |
| 12 | brk | 重置堆顶 | 61 | wait4 | 等待一个进程终止 |
| 32 | dup2 | 复制文件描述符 | 62 | kill | 发送信号到一个进程 |
C 程序用 syscall 函数可以直接调用任何系统调用。然而,实际中几乎没必要这么做。对于大多数系统调用,标准 C 库提供了一组方便的包装函数。 这些包装函数将参数打包到一起,以适当的系统调用指令陷入内核,然后将系统调用的返回状态传递回调用程序。
在本笔记中,我们将系统调用和与它们相关联的包装函数都称为 系统级函数,这两个术语可以互换地使用。
在 X86-64 系统上,系统调用是通过一条称为 syscall 的陷阱指令来提供的,那么程序如何使用 syscall 指令来直接调用 Linux 系统调用呢?
所有的 Linux 系统调用的参数都是通过通用寄存器而不是栈传递的,按照惯例:
-
寄存器 %rax 包含系统调用号
-
寄存器 %rdi、%rsi、%rdx、%r10、%r8 和 %r9 包含最多 6 个参数。第一个参数在 %rdi 中,第二个在 %rsi 中,以此类推。
-
从系统调用返回时,寄存器 %rcx 和 %r11 都会被破坏,%rax 包含返回值。
-4095 到 -1 之间的负数返回值表明发生了错误,对应于负的 errno。
例如,考虑大家熟悉的 hello 程序的下面这个版本,用系统级函数 write 来写,而不是用 printf:
int main()
{
// 第一个参数将输出发送到 stdout。第二个参数是要写的字节序列。第三个参数是要写的字节数
write(1, "hello, world\n", 13);
_exit(0);
}
其汇编代码如下:
1 .section .data
2 string:
3 .ascii "hello, world\n"
4 string_end:
5 .equ len, string_end - string
6 .section .text
7 .globl main
8 main:
## First, call write(1, "hello, world\n", 13)
9 movq $1, %rax ## write is system call 1
10 movq $1, %rdi ## Arg1: stdout has descriptor 1
11 movq $string, %rsi ## Arg2: hello world string
12 movq $len, %rdx ## Arg3: string length
13 syscall ## Make the system call
## Next, call _exit(0)
14 movq $60, %rax ## _exit is system call 60
15 movq $0, %rdi ## Arg1: exit status is 0
16 syscall ## Make the system call
直接使用 syscall 指令来调用 write 和 exit 系统调用:
- 第 9 ∼ 13 行调用 write 函数。首先,第 9 行将系统调用 write 的编号存放在 %rax 中,第 10 ∼ 12 行设置参数列表。然后第 13 行使用 syscall 指令来调用系统调用。
- 类似地,第 14 ∼ 16 行调用 _exit 系统调用。
操作系统层:进程¶
进程的经典定义就是一个执行中程序的实例。每次用户通过向 shell 输入一个可执行目标文件的名字,运行程序时,shell 就会创建一个新的进程,然后在这个新进程的上下文中运行这个可执行目标文件。应用程序也能够创建新进程,并且在这个新进程的上下文中运行它们自己的代码或其他应用程序。
本笔记不讨论操作系统如何实现进程的细节,而是将关注进程提供给应用程序的关键抽象:
- 一个独立的 逻辑控制流,它提供一个假象,好像我们的程序独占地使用处理器。
- 一个私有的地址空间,它提供一个假象,好像我们的程序独占地使用内存系统。让我们更深入地看看这些抽象。
首先会介绍什么是逻辑控制流、并发流以及私有地址空间,接着介绍用户模式和内核模式,然后介绍上下文切换,最后在此基础之上结合 Linux 系统对其提供的系统函数进行讲解。
一、逻辑控制流
如果用调试器单步执行程序,我们会看到一系列的程序计数器 PC 的值,这些值唯一地对应于包含在程序的可执行目标文件中的指令(的地址),或是包含在运行时动态链接到程序的共享对象中的指令(的地址)。
将 PC 值的序列叫做 逻辑控制流,或者简称 逻辑流。
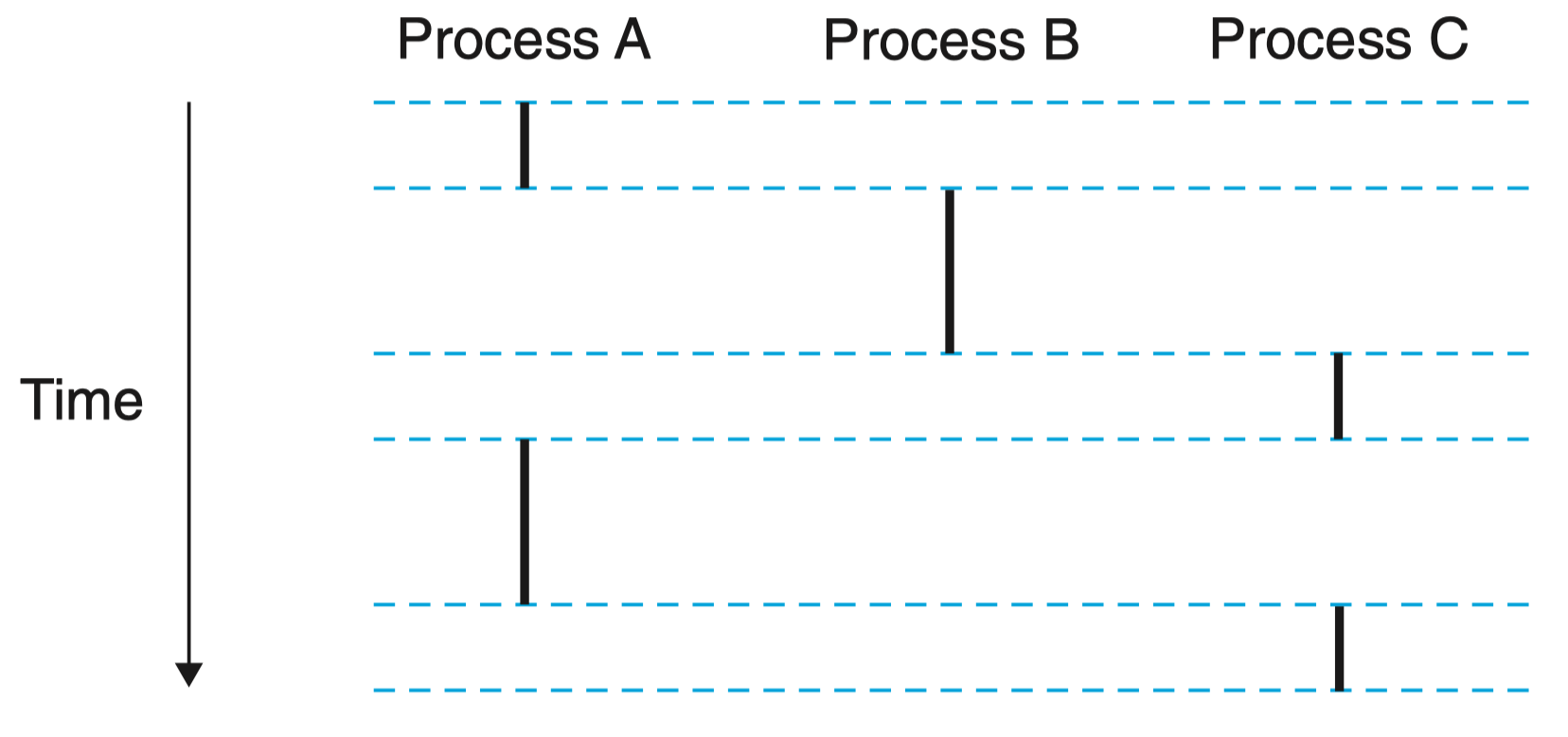
如图为运行着三个进程的系统,处理器的一个物理控制流被分成了三个逻辑流,每个进程一个。
进程 A 运行了一会,然后是进程 B 开始运行到完成。然后,进程 C 运行了一会儿,进程 A 接着运行直到完成。最后,进程 C 可以运行到结束。
关键点在于进程是轮流使用处理器的,每个进程执行它的流的一部分,然后被 抢占(preempted)(暂时挂起),然后轮到其他进程。
对于一个运行在这些进程之一的上下文中的程序,它看上去就像是在独占地使用处理器。
唯一的反面例证是,如果我们精确地测量每条指令使用的时间,会发现在程序中一些指令的执行之间,CPU 好像会周期性地停顿 。然而,每次处理器停顿,它随后会继续执行我们的程序,并不改变程序内存位置或寄存器的内容。
二、并发流
计算机系统中逻辑流有许多不同的形式。异常处理程序、进程、信号处理程序、线程和 Java 进程都是逻辑流的例子。
一个逻辑流的执行在时间上与另一个流重叠,称为 并发流(concurrent flow),这两个流被称为 并发地运行。
在上图中,进程 AB 并发运行、AC 并发运行,但 BC 没有并发地运行,因为 B 的最后一条指令在 C 的第一条指令之前执行。
一个进程和其他进程轮流运行的概念称为 多任务(multitasking)。一个进程执行它的控制流的一部分的每一时间段叫做 时间片 (time slice)。因此,多任务也叫做 时间分片(timeslicing)。例如上图中的进程 A 的流由两个时间片组成。
注意,并发流的思想与流运行的处理器核数或者计算机数无关。如果两个流在时间上重叠,那么它们就是并发的,即使它们是运行在同一个处理器上。不过,有时我们会发现确认并行流是很有帮助的,它是并发流的一个真子集。 如果两个流并发地运行在不同的处理器核或者计算机上,那么我们称它们为 并行流(parallel flow),它们 并行地运行 (running in parallel),且 并行地执行(parallel execution)。
三、私有地址空间
进程也为每个程序提供一种假象,好像它独占地使用系统地址空间。在一台 n 位地址的机器上,地址空间是 \(2^n\) 个可能地址的集合,0,1,⋯,\(2^n -1\) 。进程为每个程序提供它自己的 私有地址空间。一般而言,和这个空间中某个地址相关联的那个内存字节是不能被其他进程读或者写的,从这个意义上说,这个地址空间是私有的。
尽管和每个私有地址空间相关联的内存的内容一般是不同的,但是每个这样的空间都有相同的通用结构。
下图展示了一个 x86-64 Linux 进程的地址空间的组织结构。

地址空间底部是保留给用户程序的,包括通常的代码、数据、堆和栈段。代码段总是从地址 0x400000 开始。地址空间顶部保留给内核(操作系统常驻内存的部分)。地址空间的这个部分包含内核在代表进程执行指令时(比如当应用程序执行系统调用时)使用的代码、数据和栈。
在 X86 中通常从 0x08048000 开始,而 0x0 - 0x08048000 为未使用,该数字由链接器决定,当然可以修改,但一般都不改。
四、用户模式和内核模式
为了使操作系统内核提供一个无懈可击的进程抽象,处理器必须提供一种机制,限制一个应用可以执行的指令以及它可以访问的地址空间范围。
处理器通常是用某个控制寄存器中的一个 模式位(mode bit)来提供这种功能的,该寄存器描述了进程当前享有的特权。当设置了模式位时,进程就运行在 内核模式 中(有时叫做 超级用户模式)。一个运行在内核模式的进程可以执行指令集中的任何指令,并且可以访问系统中的任何内存位置。
没有设置模式位时,进程就运行在用户模式中。用户模式中的进程不允许执行 特权指令(privileged instruction),比如停止处理器、改变模式位,或者发起一个 I/O 操作。也不允许用户模式中的进程直接引用地址空间中内核区内的代码和数据。任何这样的尝试都会导致致命的保护故障。反之,用户程序必须通过系统调用接口间接地访问内核代码和数据。
运行应用程序代码的进程初始时是在用户模式中的。进程从用户模式变为内核模式的唯一方法是通过诸如中断、故障或者陷入系统调用这样的异常。 当异常发生时,控制传递到异常处理程序,处理器将模式从用户模式变为内核模式。处理程序运行在内核模式中,当它返回到应用程序代码时,处理器就把模式从内核模式改回到用户模式。
Linux 提供了一种聪明的机制,叫做 /proc 文件系统,它允许用户模式进程访问内核数据结构的内容。/proc
文件系统将许多内核数据结构的内容输出为一个用户程序可以读的文本文件的层次结构。比如,你可以使用 / proc 文件系统找出一般的系统属性,比如
CPU 类型(/proc/cpuinfo),或者某个特殊的进程使用的内存段(/proc/\
五、上下文切换
现在我们知道每个进程有自己的私有地址空间,且多个进程可以并发的运行。
注意到,当某个进程的时间片运行完毕后,CPU 会转而去执行另一个进程,但 CPU 的寄存器等数据却只有一套,那么如何保证在多任务执行的时候,数据的安全与正确呢?
操作系统内核使用一种称为 上下文切换(context switch)的较高层形式的异常控制流来实现多任务。
内核为每个进程维持一个 上下文(context),上下文就是内核重新启动一个被抢占的进程所需的状态,其内容包括:
- 通用目的寄存器、浮点寄存器、程序计数器、用户栈、状态寄存器、内核栈
- 各种内核数据结构,比如描述地址空间的页表、包含有关当前进程信息的进程表,以及包含进程已打开文件的信息的文件表
① 在进程执行的某些时刻,内核可以决定抢占当前进程,并重新开始一个先前被抢占了的进程。这种决策就叫做 调度 (scheduling),是由内核中称为 调度器(scheduler)的代码处理的。
当内核选择一个新的进程运行时,我们说内核调度了这个进程。在内核调度了一个新的进程运行后,它就抢占当前进程,并使用一种称为上下文切换的机制来将控制转移到新的进程:
- 保存当前进程的上下文
- 恢复某个先前被抢占的进程被保存的上下文
- 将控制传递给这个新恢复的进程。
② 当内核代表用户执行系统调用时,可能会发生上下文切换。如果系统调用因为等待某个事件发生而阻塞,那么内核可以让当前进程休眠,切换到另一个进程。
比如,如果一个 read 系统调用需要访问磁盘,内核可以选择执行上下文切换,运行另外一个进程,而不是等待数据从磁盘到达。另一个示例是 sleep 系统调用,它显式地请求让调用进程休眠。一般而言,即使系统调用没有阻塞,内核也可以决定执行上下文切换,而不是将控制返回给调用进程。
③ 中断也可能引发上下文切换。
比如,所有的系统都有某种产生周期性定时器中断的机制,通常为每 1 毫秒或每 10 毫秒。每次发生定时器中断时,内核就能判定当前进程已经运行了足够长的时间,并切换到一个新的进程。
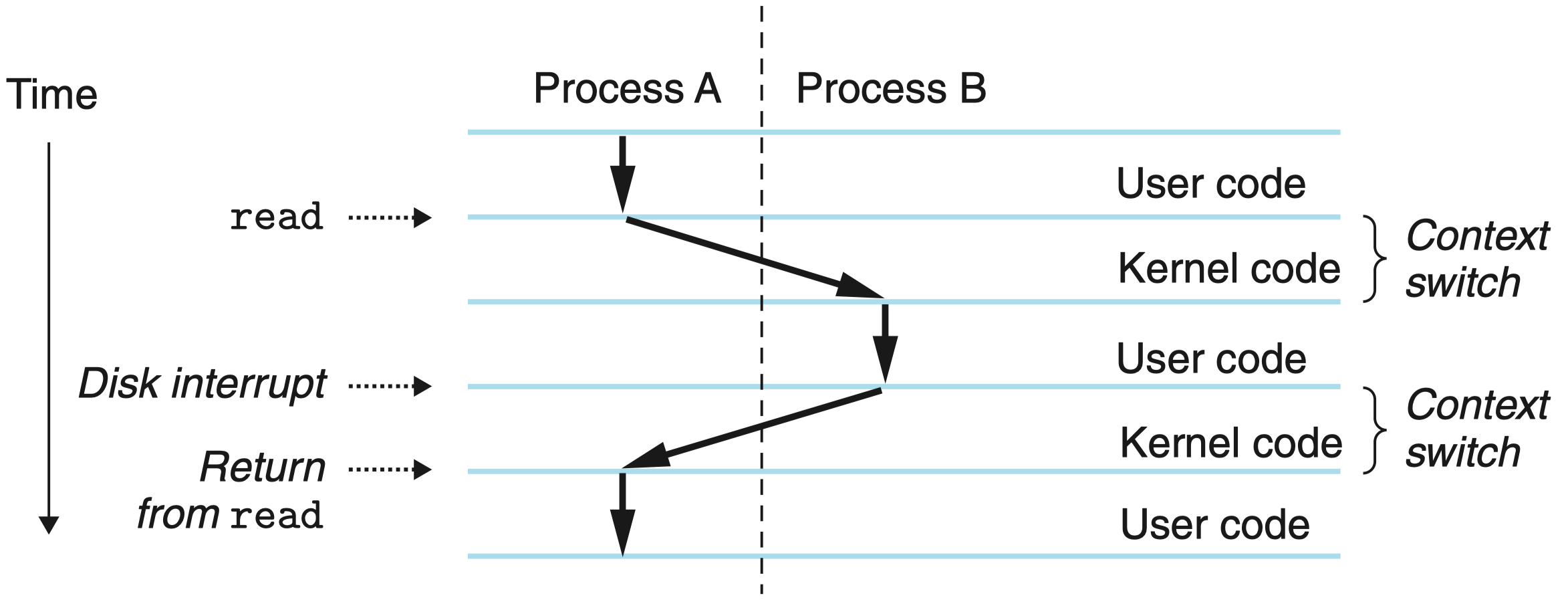
如图所示的上下文切换案例,进程 A 初始运行在用户模式中,直到它通过执行系统调用 read 陷入到内核。内核中的陷阱处理程序请求来自磁盘控制器的 DMA 传输,并且安排在磁盘控制器完成从磁盘到内存的数据传输后,磁盘中断处理器。
磁盘取数据要用一段相对较长的时间(数量级为几十毫秒),所以内核执行从进程 A 到进程 B 的上下文切换,而不是在这个间歇时间内等待,什么都不做。注意在切换之前,内核正代表进程 A 在用户模式下执行指令(即没有单独的内核进程)。在切换的第一部分中,内核代表进程 A 在内核模式下执行指令。然后在某一时刻,它开始代表进程 B(仍然是内核模式下)执行指令。在切换之后,内核代表进程 B 在用户模式下执行指令。
随后,进程 B 在用户模式下运行一会儿,直到磁盘发出一个中断信号,表示数据已经从磁盘传送到了内存。内核判定进程 B 已经运行了足够长的时间,就执行一个从进程 B 到进程 A 的上下文切换,将控制返回给进程 A 中紧随在系统调用 read 之后的那条指令。进程 A 继续运行,直到下一次异常发生,依此类推。
六、Linux 进程控制
Linux 提供了大量从 C 程序中操作进程的系统调用,包括:获取进程 ID、创建和终止进程、回收子进程、让进程休眠、加载并运行进程。
具体参考 CSAPP 513,本笔记仅对笔者认为的重点概念进行介绍。
进程总是处于下面三种状态之一:
- 运行。 进程要么在 CPU 上 执行,要么在等待被执行且最终会被内核调度。
- 停止。 进程的执行被挂起(suspended),且不会被调度。当收到 SIGSTOP、SIGTSTP、SIGTTIN 或者 SIGTTOU 信号时,进程就停止,并且保持停止直到它收到一个 SIGCONT 信号,在这个时刻,进程再次开始运行。(信号是一种软件中断的形式,将在 8.5 节中详细描述。)
- 终止。 进程永远地停止了。进程会因为三种原因终止:
- 收到一个信号,该信号的默认行为是终止进程;
- 从主程序返回;
- 调用 exit 函数。
父进程通过调用 fork 函数创建一个新的运行的子进程。
- 新创建的子进程几乎与父进程相同:
- 子进程得到与父进程用户级虚拟地址空间相同的(但是独立的)一份副本,包括代码和数据段、堆、共享库以及用户栈。
- 子进程还获得与父进程任何打开文件描述符相同的副本,这就意味着当父进程调用 fork 时,子进程可以读写父进程中打开的任何文件。
- 父进程和新创建的子进程之间最大的区别在于它们有不同的 PID。
fork 函数只被调用一次,却会返回两次:
- 一次是在调用进程(父进程)中:fork 返回子进程的 PID
- 一次是在新创建的子进程中:fork 返回 0
因为子进程的 PID 总是为非零,返回值就提供一个明确的方法来分辨程序是在父进程还是在子进程中执行。
1 int main()
2 {
3 pid_t pid;
4 int x = 1;
5 pid = Fork(); /* Fork 是对 fork 函数的包装,加入了错误判断,是 CSAPP 书中定义的,见 P512 */
6 if (pid == 0) { /* Child */
7 printf("child : x=%d\n", ++x);
8 exit(0);
9 }
/* Parent */
10 printf("parent: x=%d\n", --x);
11 exit(0);
}
当在 Unix 系统上运行这个程序时,我们得到下面的结果:
上述程序的进程图如下:
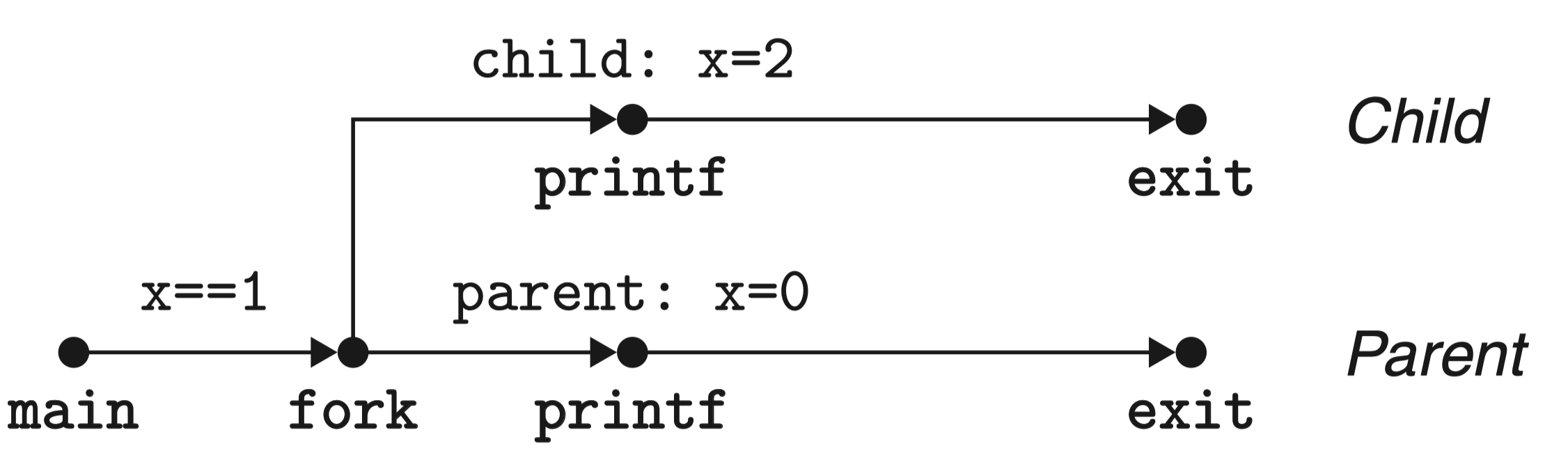
注意到第 5 行 fork 函数调用后,会新建一个子进程,由于子进程几乎是父进程的复制,因此子进程也会从第 6 行开始执行。
从结果可以注意到:
- 调用一次,返回两次:fork 函数被父进程调用一次但是返回两次,一次是返回到父进程,一次是返回到新创建的子进程。对于只创建一个子进程的程序来说,这还是相当简单直接的。但是具有多个 fork 实例的程序可能就会令人迷惑,需要仔细地推敲了。
- 并发执行:父进程和子进程是并发运行的独立进程。内核能够以任意方式交替执行它们的逻辑控制流中的指令。在我们的系统上运行这个程序时,父进程先完成它的 printf 语句,然后是子进程。然而,在另一个系统上可能正好相反。一般而言,作为程序员,我们决不能对不同进程中指令的交替执行做任何假设。
- 相同但是独立的地址空间:如果能够在 fork 函数在父进程和子进程中返回后立即暂停这两个进程,我们会看到两个进程的地址空间都是相同的。每个进程有相同的用户栈、相同的本地变量值、相同的堆、相同的全局变量值,以及相同的代码。因此,在我们的示例程序中,当 fork 函数在第 6 行返回时,本地变量 x 在父进程和子进程中都为 1。然而,因为父进程和子进程是独立的进程,它们都有自己的私有地址空间。后面,父进程和子进程对 x 所做的任何改变都是独立的,不会反映在另一个进程的内存中。这就是为什么当父进程和子进程调用它们各自的 printf 语句时,它们中的变量 x 会有不同的值。
- 共享文件:当运行这个示例程序时,我们注意到父进程和子进程都把它们的输出显示在屏幕上。原因是子进程继承了父进程所有的打开文件。当父进程调用 fork 时,stdout 文件是打开的,并指向屏幕。子进程继承了这个文件,因此它的输出也是指向屏幕的。
当一个进程由于某种原因终止时,内核并不是立即把它从系统中清除。相反,进程被保持在一种已终止的状态中,直到被它的父进程 回收 (reaped)。当父进程回收已终止的子进程时,内核将子进程的退出状态传递给父进程,然后抛弃已终止的进程,从此时开始,该进程就不存在了。一个终止了但还未被回收的进程称为 僵死进程(zombie)。
如果一个父进程终止了,内核会安排 init 进程成为它的孤儿进程的养父。init 进程的 PID 为 1,是在系统启动时由内核创建的,它不会终止,是所有进程的祖先。如果父进程没有回收它的僵死子进程就终止了,那么内核会安排 init 进程去回收它们。不过,长时间运行的程序,比如 shell 或者服务器,总是应该回收它们的僵死子进程。即使僵死子进程没有运行,它们仍然消耗系统的内存资源。
应用层:信号¶
在此之前,我们知道,异常会导致控制流突变的出现,当事件发生时,会根据异常号跳转到异常处理程序进行处理,异常由软件和硬件共同实现;随后,介绍了操作系统利用异常来支持进程上下文切换的异常控制流模式(不太理解,似乎就是上下文切换也会导致控制流突变的意思)。
在本节,将介绍更高层的 软件形式的异常,称为 Linux 信号,信号允许进程和内核中断其他进程。
一个 信号 就是一条小消息,它 通知进程 系统中发生了一个某种类型的事件。
比如,下图展示了 Linux 系统上支持的 30 种不同类型的信号(此处仅展示了部分)
| 序号 | 名称 | 默认行为 | 相应事件 |
|---|---|---|---|
| 1 | SIGHUP | 终止 | 终端线挂断 |
| 2 | SIGINT | 终止 | 来自键盘的中断 |
| 3 | SIGQUIT | 终止 | 来自键盘的退出 |
| 4 | SIGILL | 终止 | 非法指令 |
| 5 | SIGTRAP | 终止并转储内存 | 跟踪陷阱 |
| 8 | SIGFPE | 终止并转储内存 | 浮点异常 |
| 9 | SIGKILL | 终止 | 杀死程序 |
| 11 | SIGSEGV | 终止并转储内存 | 无效的内存引用(段故障) |
| 13 | SIGPIPE | 终止 | 向一个没有读用户的管道做写操作 |
| 29 | SIGIO | 终止 | 在某个描述符上可执行 I/O 操作 |
| 30 | SIGPWR | 终止 | 电源故障 |
低层的硬件异常是由内核异常处理程序处理的,正常情况下,对用户进程而言是不可见的。
信号提供了一种机制,通知用户进程发生了这些异常。
- 如果一个进程试图除以 0,那么内核就发送给它一个 SIGFPE 信号(号码 8)。
- 如果一个进程执行一条非法指令,那么内核就发送给它一个 SIGILL 信号(号码 4)。
- 如果进程进行非法内存引用,内核就发送给它一个 SIGSEGV 信号(号码 11)。
其他信号对应于内核或者其他用户进程中较高层的软件事件。:
- 如果当进程在前台运行时,你键入 Ctrl+C(也就是同时按下 Ctrl 键和 C 键),那么内核就会发送一个 SIGINT 信号(号码 2)给这个前台进程组中的每个进程。
- 一个进程可以通过向另一个进程发送一个 SIGKILL 信号(号码 9)强制终止它。
- 当一个子进程终止或者停止时,内核会发送一个 SIGCHLD 信号(号码 17)给父进程。
传送一个信号到目的进程是由两个不同步骤组成的:
-
发送信号。 内核通过更新目的进程上下文中的某个状态,发送(递送)一个信号给目的进程。发送信号可以有如下两种原因:
- 内核检测到一个系统事件,比如除零错误或者子进程终止。
- 一个进程调用了 kill 函数,显式地要求内核发送一个信号给目的进程。
一个进程可以发送信号给它自己。
- 接收信号。当目的进程被内核强迫以某种方式对信号的发送做出反应时,它就接收了信号。进程可以忽略这个信号,终止或者通过执行一个称为信号处理程序(signal handler)的用户层函数捕获这个信号。图 8-27 给出了信号处理程序捕获信号的基本思想。
注意:信号和异常的主要不同之处在于,异常是由内核异常处理程序处理的,用户层无法干预,而信号则不同,虽然每个信号类型都有一个预定义的 默认行为(进程终止、终止并转存、进程挂起知道被 SIGCONT 重启、忽略信号),但进程可以通过使用 signal 函数修改和信号相关联的默认行为。
#include <signal.h>
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
// 返回:若成功则为指向前次处理程序的指针,若出错则为 SIG_ERR(不设置 errno)。
有关进程的更多信息,可查看 CSAPP 526。
加载与执行(TODO)¶
- CSAPP P484
- CSAPP P521 TODO
- CSAPP P584 TODO
目前,我们已经首先介绍了程序从源代码经过编译与汇编生成可重定位目标程序,又经过链接器生成了可执行目标程序。此外,还知道二者用 ELF 格式的具体文件组织情况,本章将介绍可执行目标程序如何载入内存并执行的。
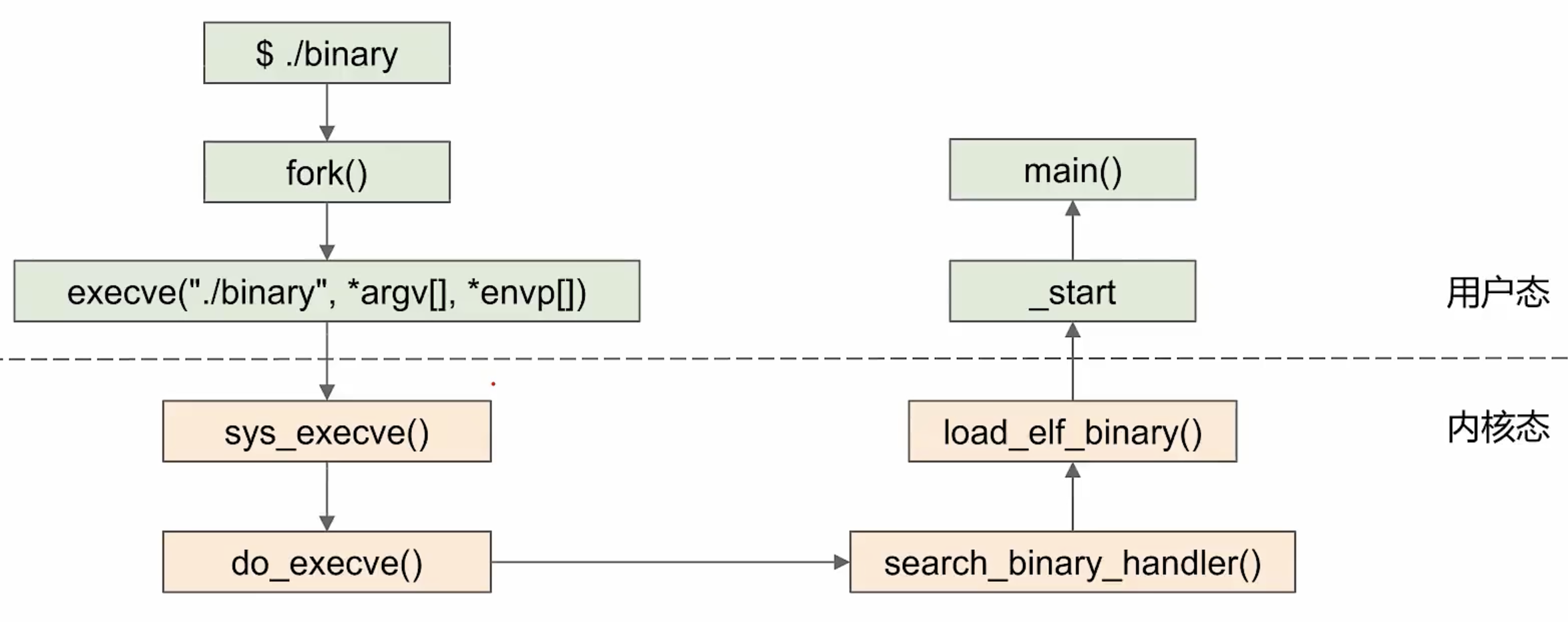
要运行可执行目标文件 a.out,只需要在 Linux shell 的命令行中输入:
由于 a.out 不是一个内置的 shell 命令,所以 shell 会认为 prog 是一个可执行目标文件,通过调用某个驻留在存储器中称为加载器(loader)的操作系统代码来运行它。
任何 Linux 程序都可以通过调用 execve 函数来调用加载器 (TODO:详细介绍)
加载器将可执行目标文件中的代码和数据从磁盘复制到内存中,然后通过跳转到程序的第一条指令或入口点来运行该程序。这个将程序复制到内存并运行的过程叫做 加载。
想要真正理解加载,必须明白进程、虚拟内存和内存映射的概念。此处仅做一个概述:
Linux 系统中的每个程序都运行在一个进程上下文中,有自己的虚拟地址空间。当 shell 运行一个程序时:
- 父 shell 进程生成一个子进程,它是父进程的一个复制。
- 子进程通过 execve 系统调用启动加载器。
- 加载器删除子进程现有的虚拟内存段,并创建一组新的代码、数据、堆和栈段。新的栈和堆段被初始化为零。通过将虚拟地址空间中的页映射到可执行文件的页大小的片(chunk),新的代码和数据段被初始化为可执行文件的内容。
- 最后,加载器跳转到_start 地址,它最终会调用应用程序的 main 函数。除了一些头部信息,在加载过程中没有任何从磁盘到内存的数据复制。直到 CPU 引用一个被映射的虚拟页时才会进行复制,此时,操作系统利用它的页面调度机制自动将页面从磁盘传送到内存。
静态链接的程序执行时如图所示:
动态链接的程序执行时如图所示:
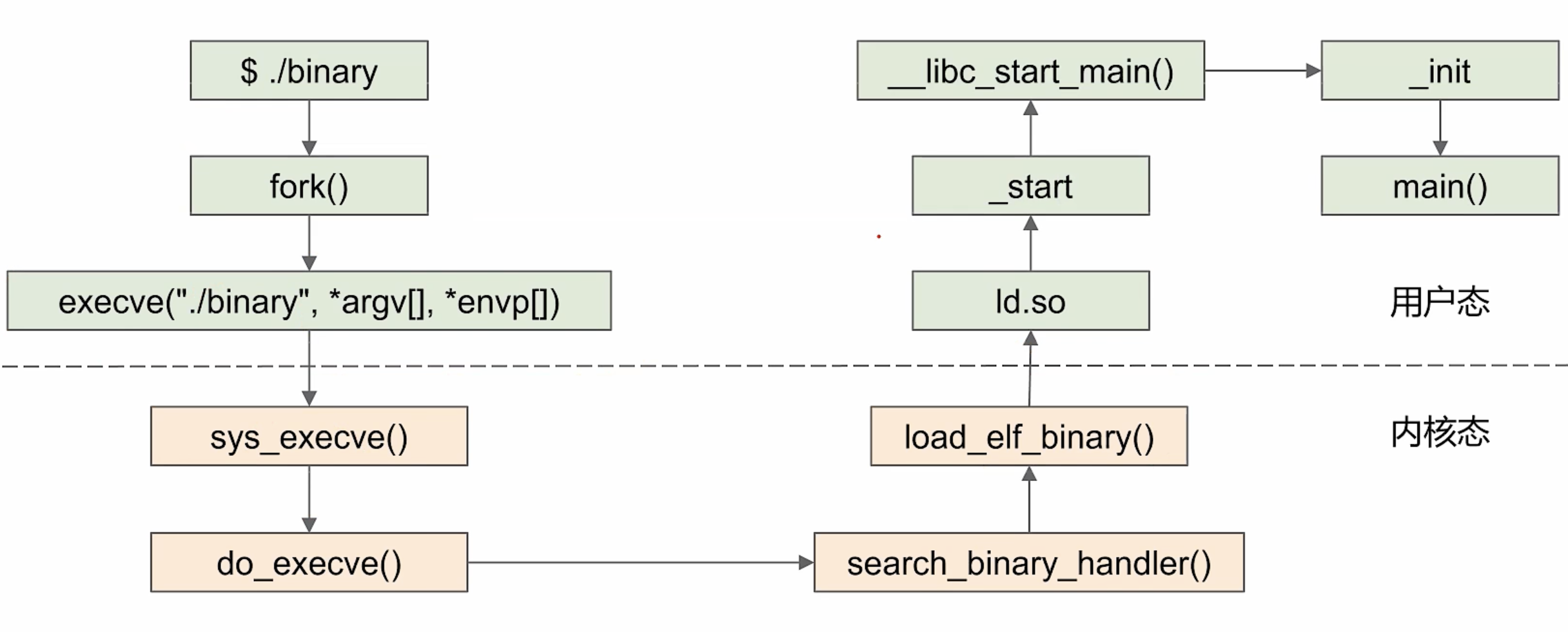
其中 ld.so 负责加载所有库及初始化 GOT(global offset table) 表。
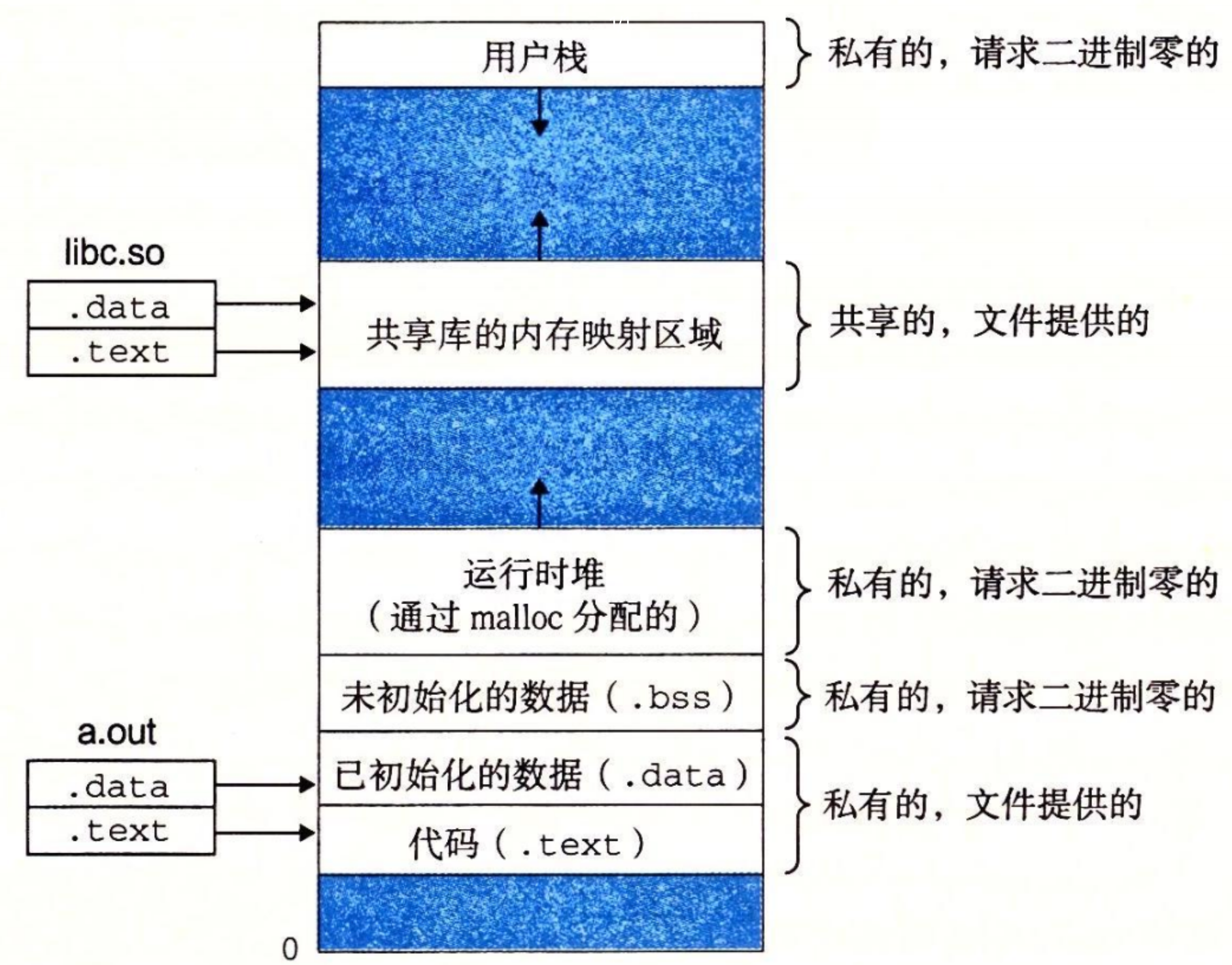
每个 Linux 程序都有一个运行时内存映像,如下图所示:
在 Linux 86-64 系统中:
- 代码段总是从地址 0x400000 处开始
- 数据段位于代码段之后:
- 运行时 堆 在数据段之后,通过调用 malloc 库往上增长。
- 堆后面的区域是为共享模块保留的。
- 用户栈总是从最大的合法用户地址( \(2^{48}−1\) )开始,向较小内存地址增长。
- 栈上的区域,从地址 \(2^{48}\) 开始,是为 内核(kernel)中的代码和数据保留的,所谓内核就是操作系统驻留在内存的部分。
虚拟内存技术使得每个进程的内存映像可以使用相同的基本格式(e.g. 代码段总是从地址 0x400000 开始),而不用管代码和数据实际存放在物理内存的何处。
为了简洁,我们把堆、数据和代码段画得彼此相邻,并且把栈顶放在了最大的合法用户地址处。实际上,由于 .data 段有对齐要求,所以代码段和数据段之间是有间隙的。同时,在分配栈、共享库和堆段运行时地址的时候,链接器还会使用地址空间布局随机化。虽然每次程序运行时这些区域的地址都会改变,它们的相对位置是不变的。
当加载器运行时,创建类似的内存映像。在程序头部表的引导下,加载器将可执行文件的片(chunk)复制到代码段和数据段。接下来,加载器跳转到程序的入口点,也就是 _start
函数的地址。这个函数是在系统目标文件 ctrl.o 中定义的,对所有的 C 程序都是一样的。_start 函数调用系统启动函数
__libc_start_main,该函数定义在 libc.so 中。它初始化执行环境,调用用户层的 main 函数,处理 main 函数的返回值,并且在需要的时候把控制返回给内核。
以 C 代码为例:
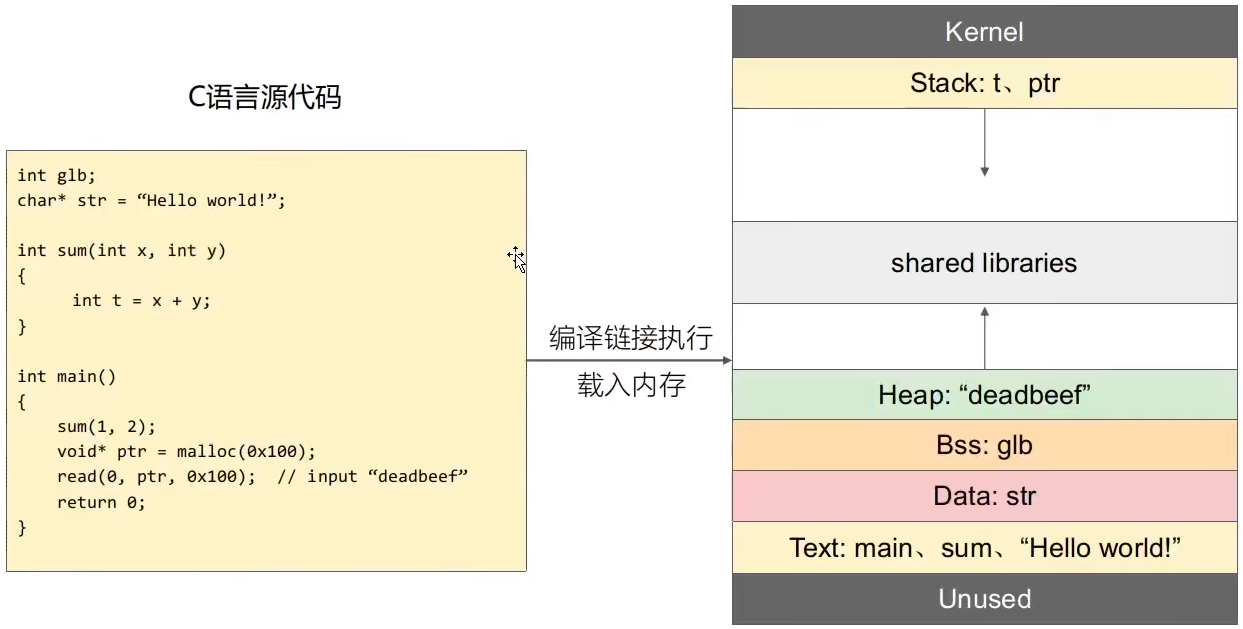
此处只是以源代码为例,实际上写入内存的是编译链接后的可执行目标文件。
- malloc 分配的是堆内存
- 局部变量和函数调用均分配在栈内存上
- glb 为未初始化的全局变量,存储在 .bss 节中,而 .bss 属于数据段 Data
- str 为已初始化的全局变量,存储在 .data 节中,.data 同样属于数据段 Data
- main、sum、“Hello world!" 等存储在 .strtab 节中,.strtab 属于代码段 Text
程序的执行
将指令交给 CPU 处理,即为执行。
虚拟内存¶
一个系统中的进程是与其他进程共享 CPU 和主存资源的。为了更加高效地管理内存并且少出错,现代系统提供了一种对主存的抽象概念,称为 虚拟内存(VM),其提供了三个重要的能力:
- VM 在主存中自动缓存最近使用的存放在磁盘上的虚拟地址空间的内容,虚拟内存缓存中的块叫做页。对磁盘上页的引用会触发缺页,缺页将控制转移到操作系统中的缺页处理程序。缺页处理程序将页从磁盘复制到主存缓存,如果必要,将写回被驱逐的页。
- VM 简化了内存管理,进而又简化了链接、在进程间共享数据、进程的内存分配以及程序加载。
- VM 通过在每条页表条目加入保护位,从而简化了内存保护。
在本章节中将首先介绍 物理和虚拟寻址,随后给出 地址空间 的概念。然后介绍什么是 虚拟内存,并给出虚拟内存扮演的工具角色:
- 虚拟内存作为缓存的工具
- 虚拟内存作为内存管理的工具
- 虚拟内存作为内存保护的工具
这三种工具属性也正对应了上面介绍的虚拟内存的三个重要能力。为了让你更了解硬件在支持虚拟内存中扮演的角色,将介绍 地址翻译 (省略了大量细节,例如时序),在此期间,你将理解:① 如何结和高速缓存和虚拟内存 ② 快表 TLB ③ 多级页表。
最后,结合 Linux 虚拟内存系统作为结尾,给出 内存映射 的概念,对 Linux 系统函数进行更深入的理解,并以动态分配内存结尾,给出 垃圾回收 的基本知识。
一、物理和虚拟寻址¶
计算机系统的主存被组织成一个由 M 个连续的字节大小的单元组成的数组。每字节都有一个唯一的 物理地址(Physical Address,PA)。
CPU 直接使用物理地址访问内存,称为 物理寻址。
早期的 PC 使用物理寻址,而且诸如数字信号处理器、嵌入式微控制器以及 Cray 超级计算机这样的系统仍然继续使用这种寻址方式。
现代处理器使用的是一种称为 虚拟寻址(virtual addressing)的寻址形式,如图所示:
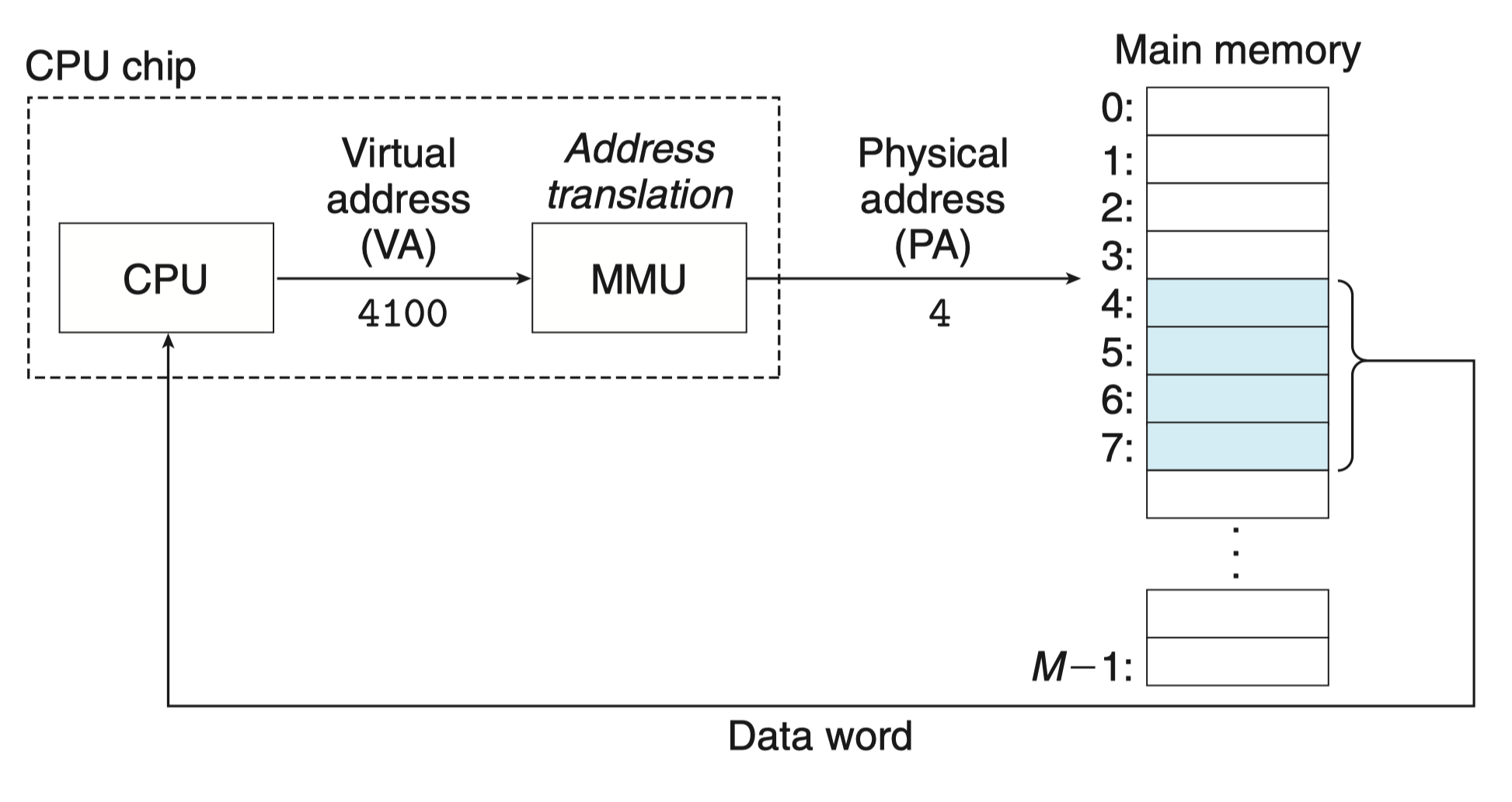
为了使用虚拟寻址,CPU 首先会生成一个 虚拟地址(Virtual Address,VA)来访问主存,这个虚拟地址在被送到内存之前先转换成适当的物理地址,转换的过程叫做 地址翻译(address translation)。
就像异常处理一样,地址翻译需要 CPU 硬件和操作系统之间的紧密合作。
CPU 芯片上名为 内存管理单元(Memory Management Unit,MMU)的专用硬件,利用存放在主存中的查询表来动态翻译虚拟地址,该表的内容由操作系统管理。
二、地址空间¶
地址空间(addressspace)是一个非负整数地址的有序集合,如果地址空间中的整数是连续的,那么我们说它是一个 线性地址空间 (linear address space)。
为了简化讨论,我们总是假设使用的是线性地址空间。
在一个带虚拟内存的系统中,CPU 从一个有 \(N=2^n\) 个地址的地址空间中生成虚拟地址,这个地址空间称为 虚拟地址空间(virtual addres sspace):
一个地址空间的大小是由表示最大地址所需要的位数来描述的。例如,一个包含 \(N=2^n\) 个地址的虚拟地址空间就叫做一个 n 位地址空间。现代系统通常支持 32 位或者 64 位虚拟地址空间。
一个系统还有一个 物理地址空间(physical address space),对应于系统中物理内存的 M 个字节:
M 不要求是 2 的幕,但是为了简化讨论,我们假设 \(M=2^m\)
地址空间的概念将数据对象(字节)和对象的属性(地址)拆分为两个主体,而非统一的内容。
也就是说,每个数据对象可以有多个独立的地址,其中每个地址都选自一个不同的地址空间,这就是虚拟内存的基本思想。
主存中的每字节都有一个选自虚拟地址空间的虚拟地址和一个选自物理地址空间的物理地址。
三、虚拟内存的作用¶
概念上而言,虚拟内存被组织为一个由存放在磁盘上的 N 个连续的字节大小的单元组成的数组,每字节都有一个唯一的虚拟地址,作为到数组的索引。
3.1 虚拟内存作为缓存的工具¶
磁盘上数组的内容被缓存在主存中。和存储器层次结构中其他缓存一样,磁盘(较低层)上的数据被分割成块,这些块作为磁盘和主存(较高层)之间的传输单元。
VM 系统对内存如下操作以处理上述情况:
-
虚拟内存分割为称为 虚拟页(Virtual Page,VP)的大小固定的块,每个虚拟页的大小为 \(P=2^p\) 字节。
-
物理内存被分割为 物理页(Physical Page,PP),大小也为 \(P\) 字节。物理页也被称为 页帧(page frame)
在任意时刻,虚拟页面的集合都分为三个不相交的子集:
-
未分配的: VM 系统还未分配(或者创建)的页。未分配的块没有任何数据和它们相关联,因此也就不占用任何磁盘空间。
-
缓存的: 当前已缓存在物理内存中的已分配页。
-
未缓存的: 未缓存在物理内存中的已分配页。
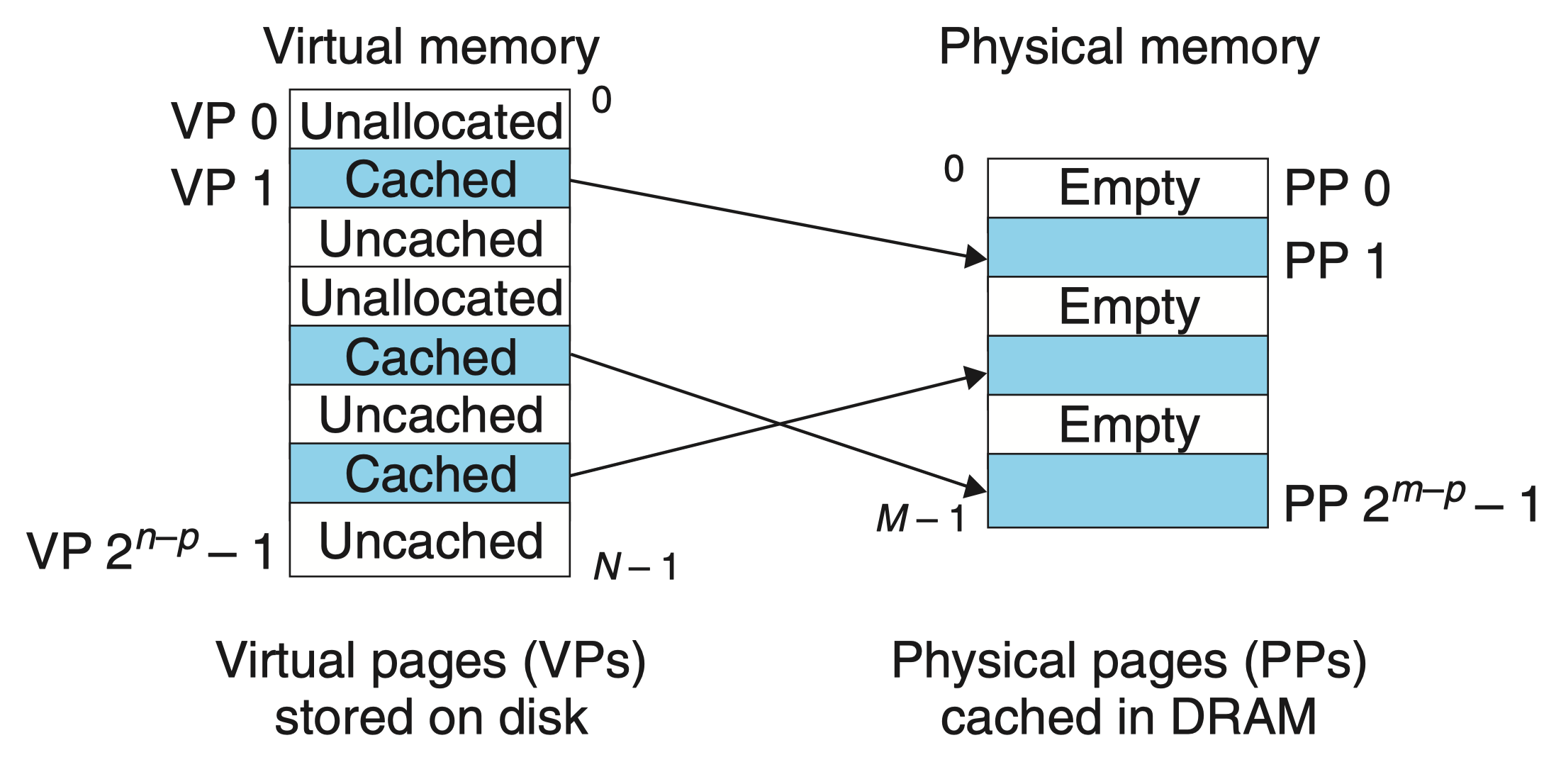
图中的示例展示了一个有 8 个虚拟页的小虚拟内存。虚拟页 0 和 3 还没有被分配,因此在磁盘上还不存在。虚拟页 1、4 和 6 被缓存在物理内存中。页 2、5 和 7 已经被分配了,但是当前并未缓存在主存中。
可以看到,虚拟内存存储在磁盘中,而 VM 系统将主存作为虚拟内存的缓存。
在《处理器层次结构》章节,曾介绍了 SRAM 和 DRAM,本节中,笔者使用术语 SRAM 缓存来表示位于 CPU 和主存之间的 L1、L2 和 L3 高速缓存,使用 DRAM 缓存来表示虚拟内存系统的缓存,也就是主存(在主存中缓存虚拟页)。
由于 DRAM 比 SRAM 约慢 10 倍,而磁盘比 DRAM 慢约 10w 倍,因此,DRAM 不命中的代价远大于 SRAM 不命中。
基于此,为了尽可能的让 DRAM 命中,虚拟页往往很大(4KB~2MB),而且不命中时的替换策略也十分重要,因为替换错虚拟页的代价也很昂贵!
为了能使虚拟内存系统成功运行,需要解决如下问题:
- 如何判定一个虚拟页是否已经缓存在 DRAM 中?
- 若是,这个虚拟页存放在哪个物理页中?
- 若不是,这个虚拟页存放在磁盘的那个位置?
上述功能由软硬件联合提供,包括操作系统软件、MMU(内存管理单元)中的地址翻译硬件和存放在物理内存(主存)中的叫做 页表 的数据结构。
每次地址翻译硬件将一个虚拟地址转换为物理地址时,都会读取页表。操作系统负责维护页表的内容,以及在磁盘与 DRAM 之间来回传送页。
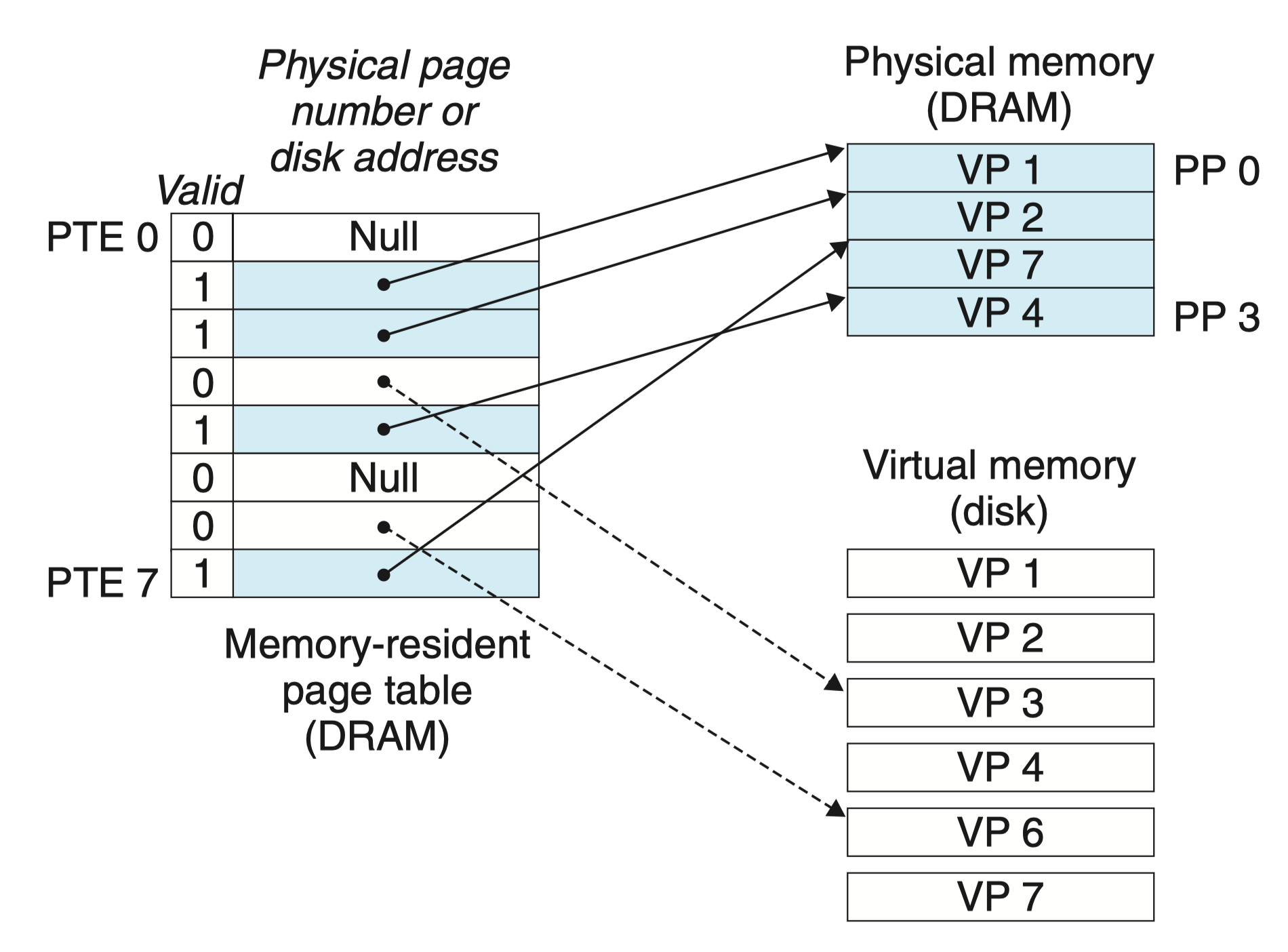
如图所示,页表是一个数组,其中每个元素称为页表条目(Page Table Entry, PTE),而 虚拟地址空间中的每个页在页表中一个固定偏移量处都有一个 PTE。
图中,PTE 由有效位和 n 位地址字段组合而成(后续将对 PTE 进行进一步扩展):
- 有效位:该虚拟页是否被缓存在 DRAM 中
- 地址字段
- 若有效位为 1,则地址字段为物理页的起始地址
- 若有效位为 0
- 若为空地址,则表示该虚拟页还未被分配
- 否则,地址字段为虚拟页在磁盘上的起始地址
图例中一共有 8 个虚拟页和 4 个物理页的系统的页表:
- 四个虚拟页(VP 1、VP 2、VP 4 和 VP 7)当前被缓存在 DRAM 中
- 两个页(VP 0 和 VP 5 )还未被分配
- 剩下的两个虚拟页(VP 3 和 VP 6)已经被分配了,但是当前还未被缓存
页命中
当 CPU 想读取包含在虚拟页 VP2 中的一个字时,首先地址翻译硬件将虚拟地址作为一个索引来定位 PTE2,并从内存中读取它,由于图中有效位为 1,此时地址翻译硬件知道虚拟页已被缓存在 DRAM 主存中,此处的地址字段为物理页的起始地址。
通过 物理页的起始地址 + 字的页内偏移量,即可得到该字的物理地址。
缺页
DRAM 缓存不命中称为缺页(page fault)。
当 CPU 想读取包含在虚拟页 VP3 中的一个字时,类似的,从内存中定位并读取 PTE3,发现有效位为 0,但地址字段不为空,推断出 VP3 已分配但未被缓存,于是 触发缺页异常。
缺页异常调用内核中的缺页异常处理程序,该程序会选择一个牺牲页,假设牺牲页为 VP4,若 VP4 已经被修改,那么内核就需要将它复制回磁盘,接着修改 VP4 对应的页表条目。
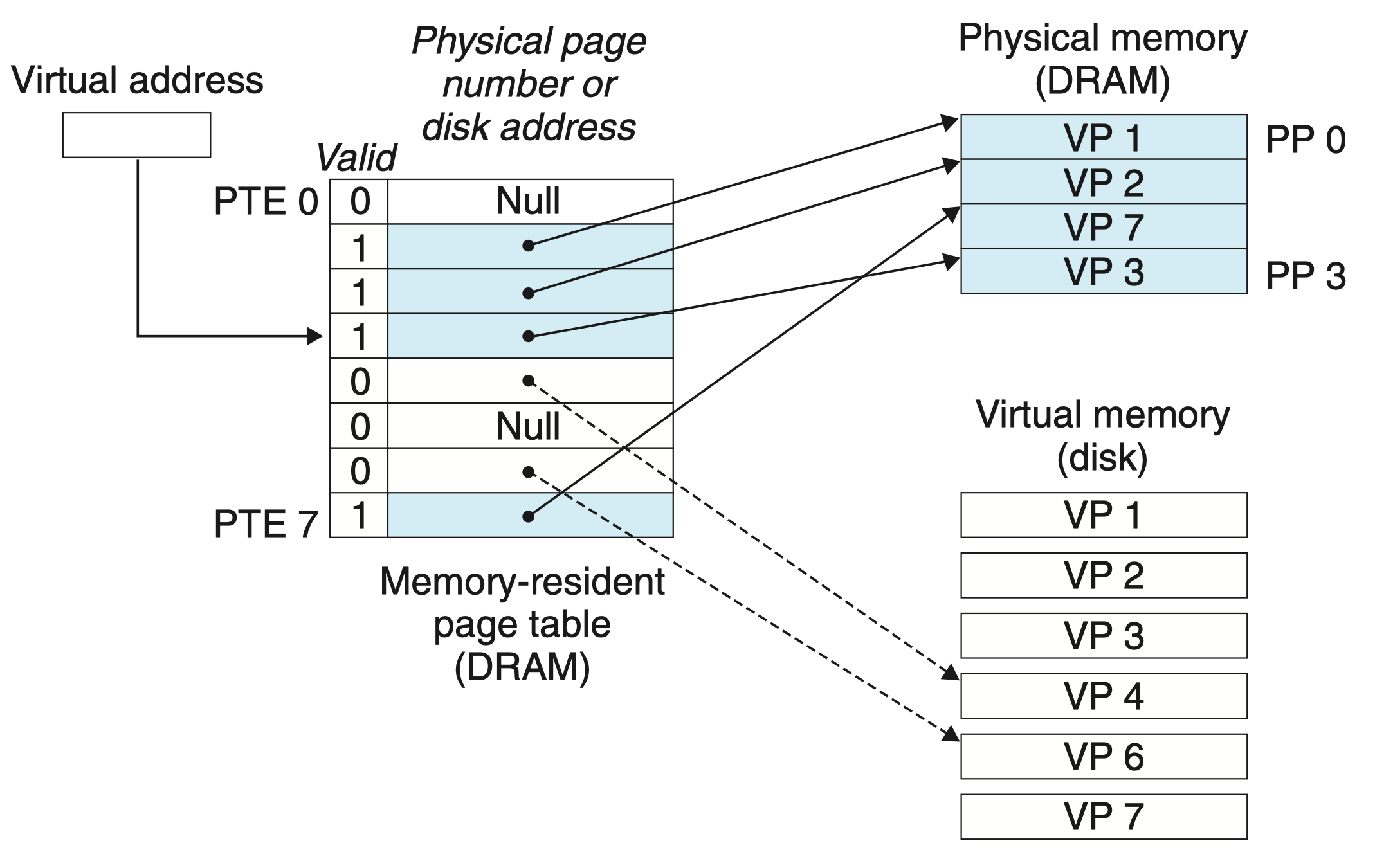
接下来,缺页异常程序将让内核从磁盘复制 PV3 到内存中的 PP3,更新 PTE3,随后返回。
当异常处理程序返回时,它会重新启动导致缺页的指令(再次读取 VP3 中的字),如图所示,此时 VP4 已被牺牲,而 VP3 成功缓存至主存 DRAM 中,同时页表也进行了相应修改,页面能成功命中。
虚拟内存的发明远远早于 CPU-内存之间差距加大引发产生 SRAM 之前,因此虚拟内存系统使用了和 SRAM 缓存不同的术语,即使他们的许多概念是相似的。
在虚拟内存的习惯说法中,块被称为页,在磁盘和内存之间传送页的活动叫做交换(swapping)或者页面调度(paging)。
所有现代系统均使用 按需页面调度 策略:页从磁盘换入 DRAM 和从 DRAM 换出磁盘,一直等待直到当不命中发生时才换入页面。
分配页面
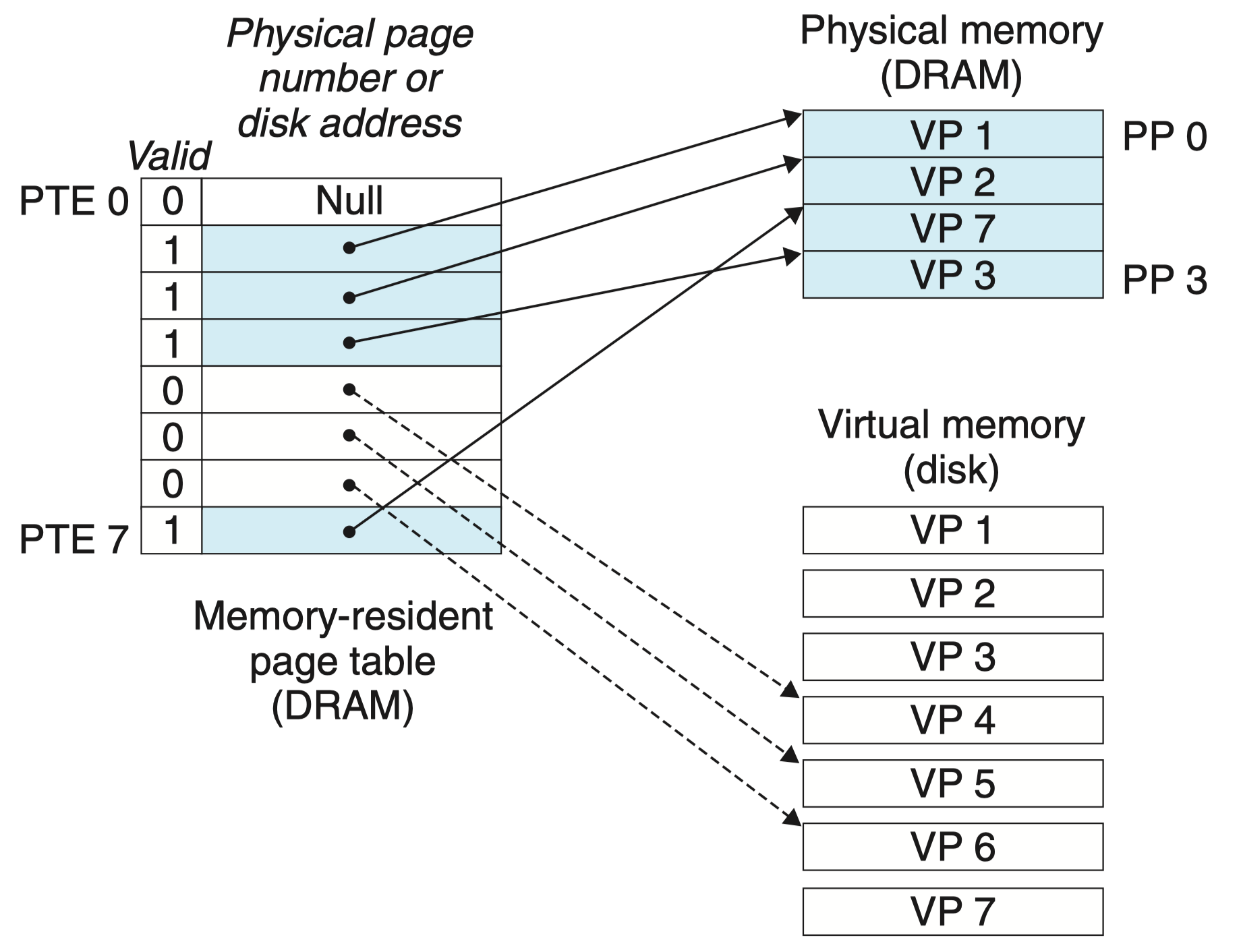
当操作系统分配一个新的虚拟内存页时(例如调用 malloc),假设分配 VP5,其过程为在磁盘上创建空间并更新 PTE5,使它指向在磁盘上新创建的页面,但并不更新有效位,因为该虚拟页未被读取,因此没有缓存到主存 DRAM 中。
局部性
尽管在整个运行过程中程序引用的不同页面的总数可能超出物理内存总的大小,但是局部性原则保证了在任意时刻,程序将趋向于在一个较小的 活动页面(active page)集合上工作,这个集合叫做 工作集(working set)或者 常驻集合(resident set)。在初始开销,也就是将工作集页面调度到内存中之后,接下来对这个工作集的引用将导致命中,而不会产生额外的磁盘流量。
只要我们的程序有好的时间局部性,虚拟内存系统就能工作得相当好。但是,当然不是所有的程序都能展现良好的时间局部性。如果工作集的大小超出了物理内存的大小,那么程序将产生一种不幸的状态,叫做 抖动(thrashing),这时页面将不断地换进换出。虽然虚拟内存通常是有效的,但是如果一个程序性能慢得像爬一样,那么聪明的程序员会考虑是不是发生了抖动。
3.2 虚拟内存作为内存管理的工具¶
通常来说虚拟地址空间往往比物理地址空间大得多,此时虚拟内存将 DRAM 作为缓存。但有趣的是,一些早期的系统支持的是一个比物理内存更小的虚拟地址空间。然后,虚拟空间仍然是一个有用的机制,因为它可以大大简化内存管理,并且提供一种自然的保护内存的方法。
到目前为止,我们都假设有一个单独的页表,将一个虚拟地址空间映射到物理地址空间。实际上,操作系统为每个进程提供了一个独立的页表,因而也就是一个独立的虚拟地址空间。
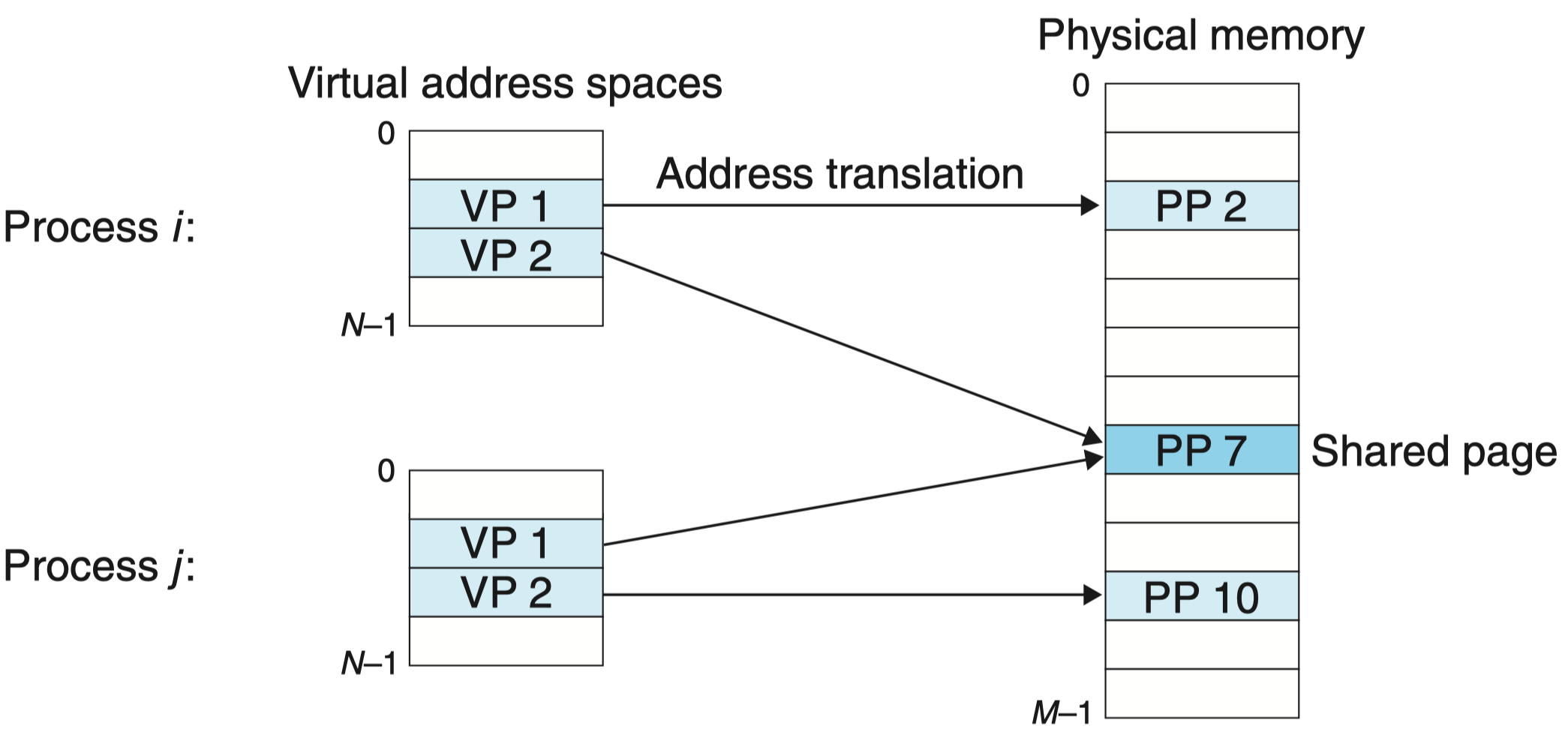
在这个示例中,进程 i 的页表将 VP 1 映射到 PP 2,VP 2 映射到 PP 7。相似地,进程 j 的页表将 VP 1 映射到 PP 7,VP 2 映射到 PP 10。注意,多个虚拟页面可以映射到同一个共享物理页面上。
按需页面调度和独立的虚拟地址空间的结合,对系统中内存的使用和管理造成了深远的影响。特别地,VM 简化了链接和加载、代码和数据共享,以及应用程序的内存分配。
-
简化链接。 独立的地址空间允许每个进程的内存映像使用相同的基本格式,而不管代码和数据实际存放在物理内存的何处。例如,一个给定的 Linux 系统上的每个进程都使用类似的内存格式。对于 64 位地址空间,代码段总是从虚拟地址 0x400000 开始。数据段跟在代码段之后,中间有一段符合要求的对齐空白。栈占据用户进程地址空间最高的部分,并向下生长。这样的一致性极大地简化了链接器的设计和实现,允许链接器生成完全链接的可执行文件,这些可执行文件是独立于物理内存中代码和数据的最终位置的。
-
简化加载。 虚拟内存还使得容易向内存中加载可执行文件和共享对象文件。要把目标文件中 .text 和 .data 节加载到一个新创建的进程中,Linux 加载器为代码和数据段分配虚拟页,把它们标记为无效的(即未被缓存的),将页表条目指向目标文件中适当的位置。有趣的是,加载器从不从磁盘到内存实际复制任何数据。在每个页初次被引用时,要么是 CPU 取指令时引用的,要么是一条正在执行的指令引用一个内存位置时引用的,虚拟内存系统会按照需要自动地调入数据页。
将一组连续的虚拟页映射到任意一个文件中的任意位置的表示法称作 内存映射(memory mapping)。Linux 提供一个称为 mmap 的系统调用,允许应用程序自己做内存映射。
- 简化共享。 独立地址空间为操作系统提供了一个管理用户进程和操作系统自身之间共享的一致机制。一般而言,每个进程都有自己私有的代码、数据、堆以及栈区域,是不和其他进程共享的。在这种情况中,操作系统创建页表,将相应的虚拟页映射到不连续的物理页面。
然而,在一些情况中,还是需要进程来共享代码和数据。例如,每个进程必须调用相同的操作系统内核代码,而每个 C 程序都会调用 C 标准库中的程序,比如 printf。操作系统通过将不同进程中适当的虚拟页面映射到相同的物理页面,从而安排多个进程共享这部分代码的一个副本,而不是在每个进程中都包括单独的内核和 C 标准库的副本,如上图所示。
- 简化内存分配。 虚拟内存为向用户进程提供一个简单的分配额外内存的机制。当一个运行在用户进程中的程序要求额外的堆空间时(如调用 malloc 的结果),操作系统分配一个适当数字(例如 k)个连续的虚拟内存页面,并且将它们映射到物理内存中任意位置的 k 个任意的物理页面。由于页表工作的方式,操作系统没有必要分配 k 个连续的物理内存页面。页面可以随机地分散在物理内存中。
3.3 虚拟内存作为内存保护的工具¶
任何现代计算机系统必须为操作系统提供手段来控制对内存系统的访问:
- 不应该允许一个用户进程修改它的只读代码段。
- 不应该允许它读或修改任何内核中的代码和数据结构。
- 不应该允许它读或者写其他进程的私有内存
- 不允许它修改任何与其他进程共享的虚拟页面,除非所有的共享者都显式地允许它这么做(通过调用明确的进程间通信系统调用)。
提供独立的地址空间使得区分不同进程的私有内存变得容易。但是,地址翻译机制可以以一种自然的方式扩展到提供更好的访问控制。因为每次 CPU 生成一个地址时,地址翻译硬件都会读一个 PTE,所以通过在 PTE 上添加一些额外的许可位来控制对一个虚拟页面内容的访问十分简单。
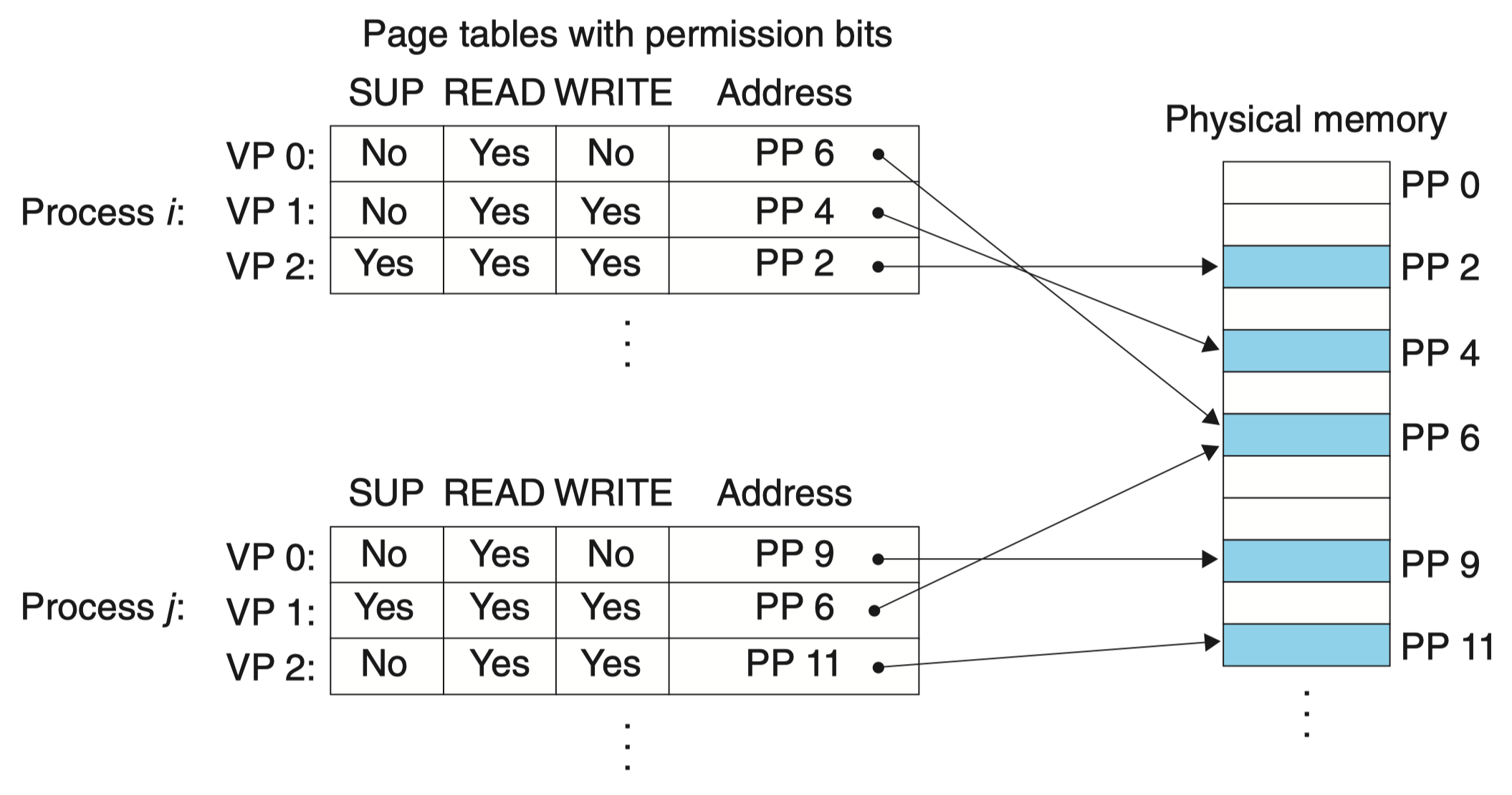
如图所示,每个 PTE 中已经添加了三个许可位。SUP 位表示进程是否必须运行在内核(超级用户)模式下才能访问该页。运行在内核模式中的进程可以访问任何页面,但是运行在用户模式中的进程只允许访问那些 SUP 为 0 的页面。READ 位和 WRITE 位控制对页面的读和写访问。例如,如果进程 i 运行在用户模式下,那么它有读 VP 0 和读写 VP 1 的权限。然而,不允许它访问 VP 2。
如果一条指令违反了这些许可条件,那么 CPU 就触发一个一般保护故障,将控制传递给一个内核中的异常处理程序。Linux shell 一般将这种异常报告为“段错误(segmentation fault)”。
四、地址翻译¶
如图展示了 MMU 如何利用页表来实现虚拟地址空间中的元素和物理空间中的元素的映射。
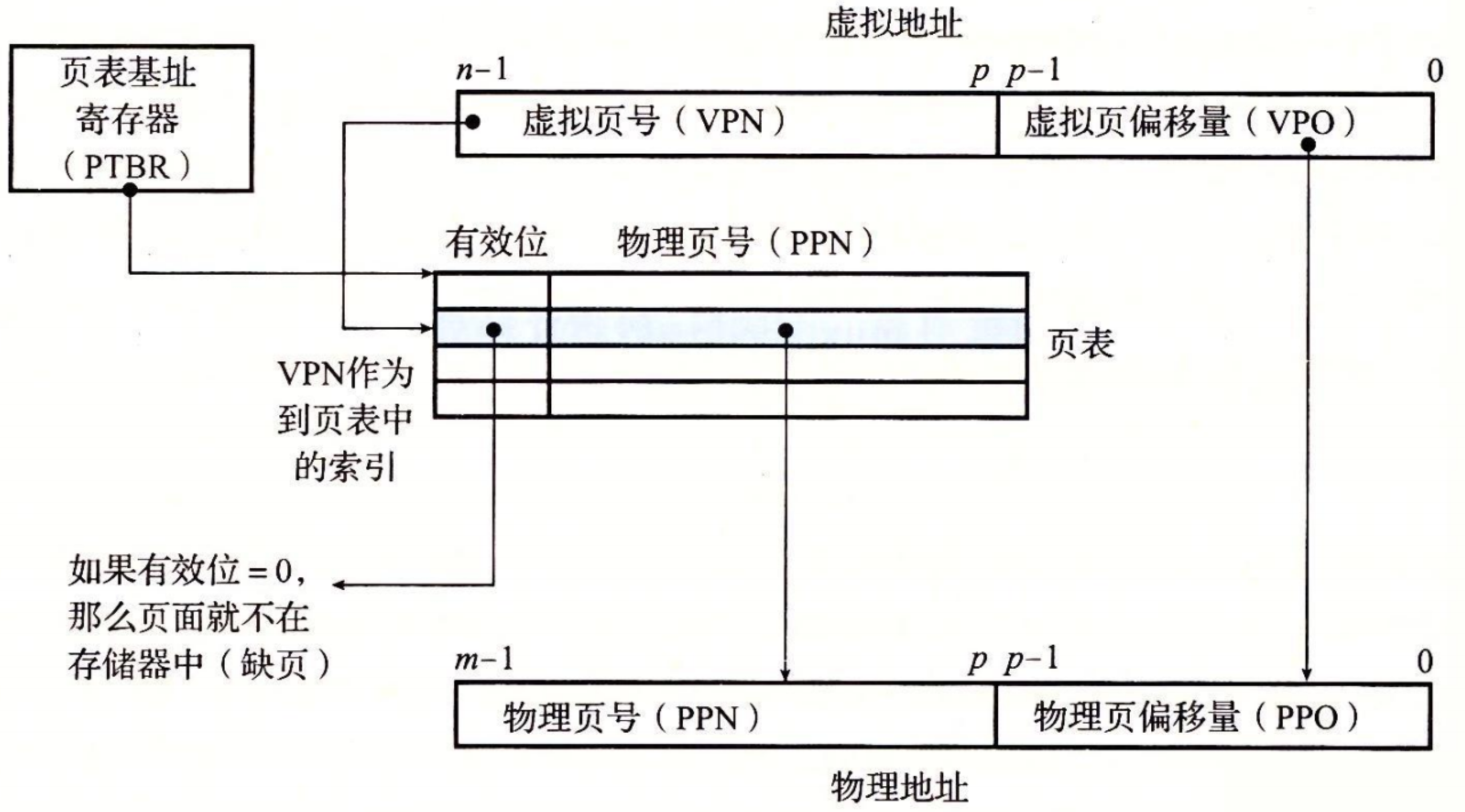
CPU 中的一个控制寄存器,页表基址寄存器(Page Table Base Register,PTBR)指向当前页表。
n 位的虚拟地址包含两个部分:一个 p 位的 虚拟页面偏移(Virtual Page Offset,VPO)和一个 n-p 位的 虚拟页号(Virtual Page Number,VPN)。
MMU 利用 VPN 来选择适当的 PTE。例如,VPN 0 选择 PTE 0,VPN 1 选择 PTE 1,以此类推。将页表条目中 物理页号(Physical Page Number,PPN)和虚拟地址中的 VPO 串联起来,就得到相应的物理地址。
注意,因为物理和虚拟页面都是 P 字节的,所以 物理页面偏移(Physical Page Offset,PPO)和 VPO 是相同的。
更详细参考 CSAPP 568。
结合高速缓存和虚拟内存
将页表条目 PTE 存储在高速缓存 SRAM 中。
利用 TLB 加速地址翻译
正如我们看到的,每次 CPU 产生一个虚拟地址,MMU 就必须查阅一个 PTE,以便将虚拟地址翻译为物理地址。
若结合了高速缓存,那么如果 PTE 碰巧缓存在 SRAM 中,那么开销就得到一定程度的下降。
为了进一步节约开销,许多系统在 MMU 中包括了一个关于 PTE 的小的缓存,称为 快表(Translation Lookaside Buffer,TLB)。
TLB 是一个小的、虚拟寻址的缓存,其中每一行都保存着一个由单个 PTE 组成的块。
多级页表
我们一直假设系统只用一个单独的页表来进行地址翻译。但是如果我们有一个 32 位的地址空间、4KB 的页面和一个 4 字节的 PTE,那么即使应用所引用的只是虚拟地址空间中很小的一部分,也总是需要一个 4MB 的页表驻留在内存中。对于地址空间为 64 位的系统来说,问题将变得更复杂。
用来 压缩页表 的常用方法是 使用层次结构的页表。
假设 32 位虚拟地址空间被分为 4KB 的页,而每个页表条目都是 4 字节。还假设在这一时刻,虚拟地址空间有如下形式:内存的前 2K 个页面分配给了代码和数据,接下来的 6K 个页面还未分配,再接下来的 1023 个页面也未分配,接下来的 1 个页面分配给了用户栈。
下图展示了我们如何为这个虚拟地址空间构造一个两级的页表层次结构:
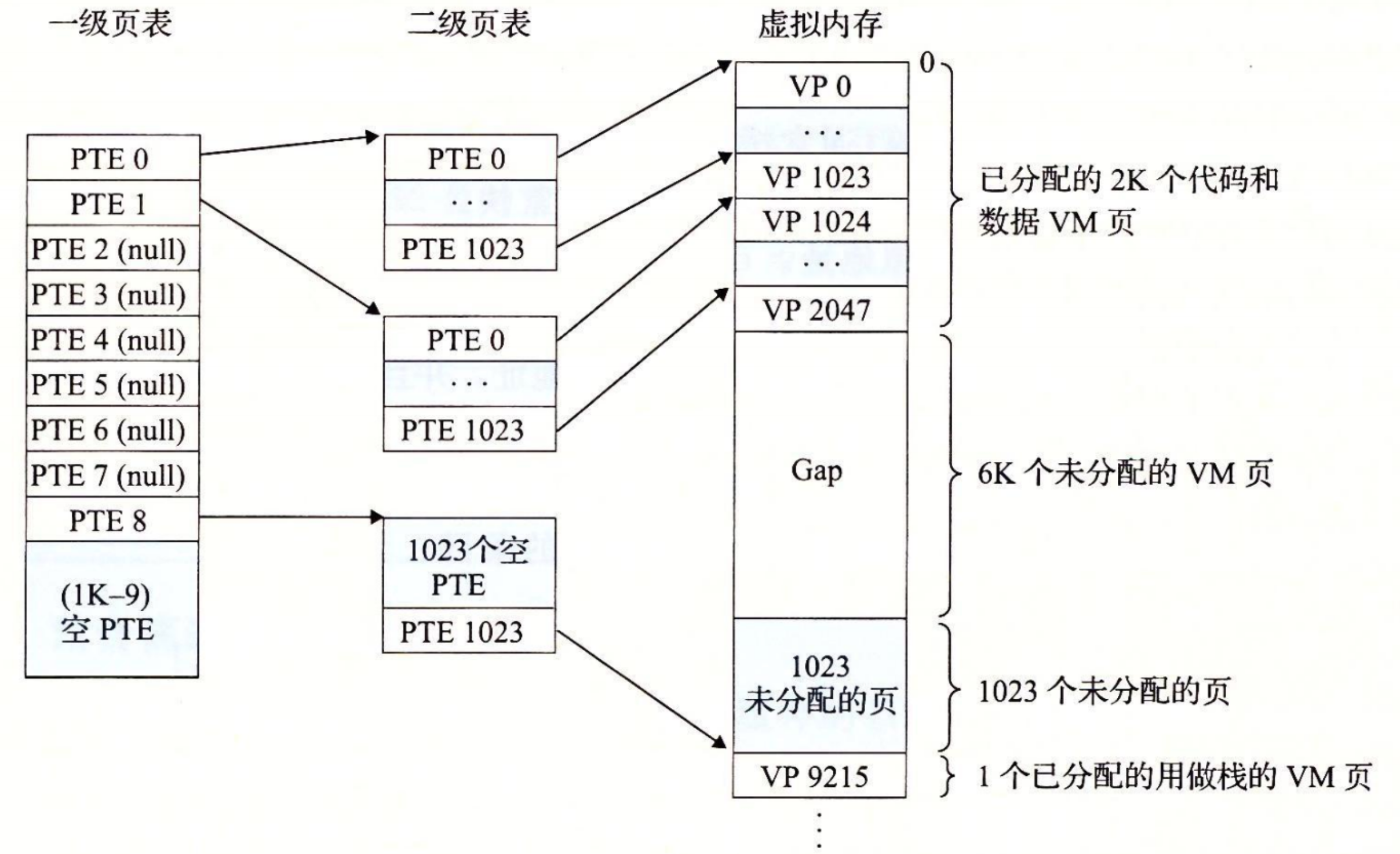
一级页表中的每个 PTE 负责映射虚拟地址空间中一个 4MB 的 片(chunk),这里每一片都是由 1024 个连续的页面组成的。比如,PTE 0 映射第一片,PTE 1 映射接下来的一片,以此类推。假设地址空间是 4GB,1024 个 PTE 已经足够覆盖整个空间了。
二级页表中的每个 PTE 都负责映射一个 4KB 的虚拟内存页面,就像我们查看只有一级的页表一样。注意,使用 4 字节的 PTE,每个一级和二级页表都是 4KB 字节,这刚好和一个页面的大小是一样的。
这种方法从两个方面减少了内存要求:
- 第一,如果一级页表中的一个 PTE 是空的,那么相应的二级页表就根本不会存在。这代表着一种巨大的潜在节约,因为对于一个典型的程序,4GB 的虚拟地址空间的大部分都会是未分配的。
- 第二,只有一级页表才需要总是在主存中;虚拟内存系统可以在需要时创建、页面调入或调出二级页表,这就减少了主存的压力;只有最经常使用的二级页表才需要缓存在主存中。
由于更改了页表结构,虚拟地址也需要进行相应的修改:
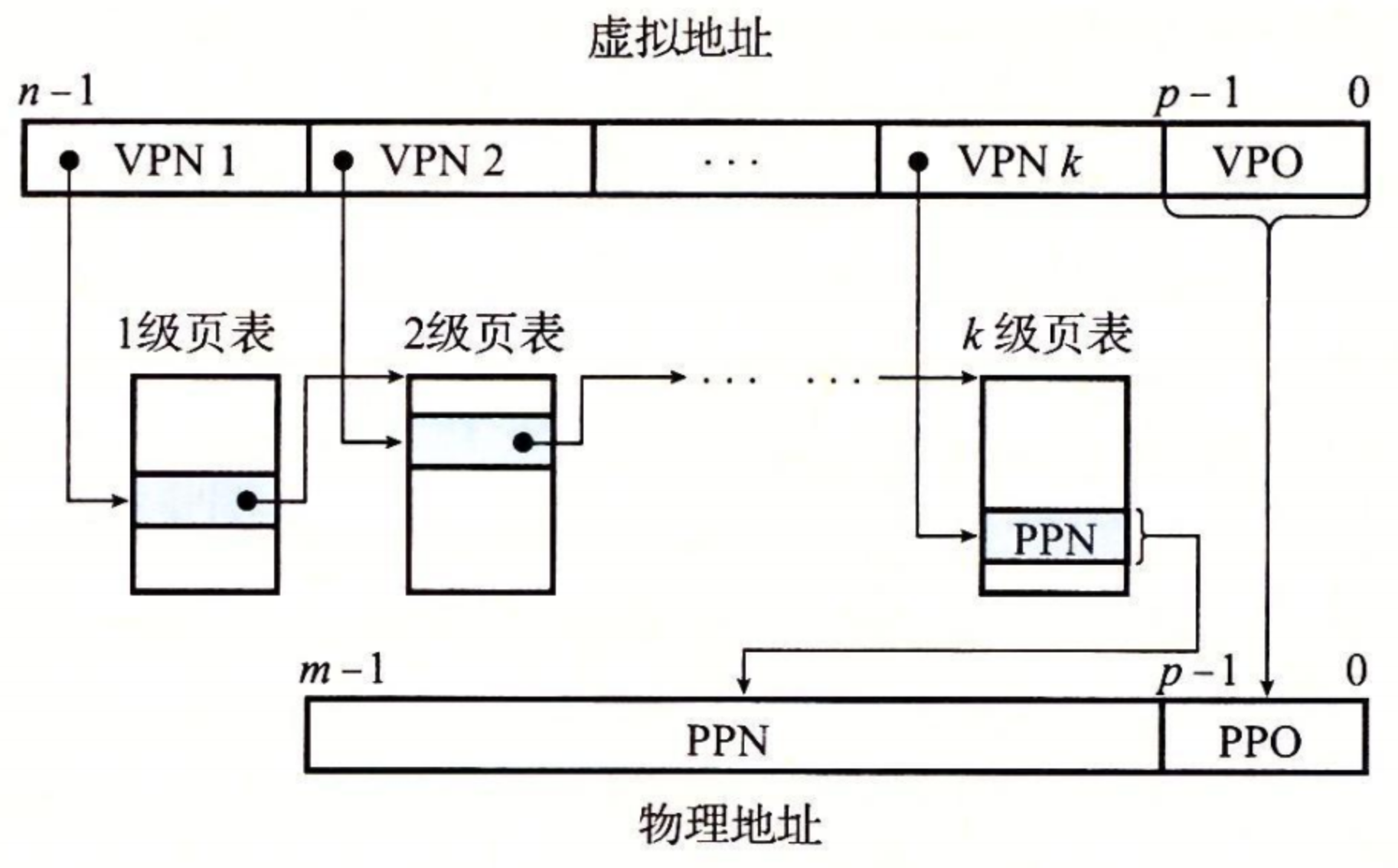
VPN1 代表一级页表,每个高级页表的 PTE 都指向其子级页表的基址,VPN k 则指向对应的物理地址(或磁盘上的虚拟页面地址)。
为了构造物理地址,在能够确定 PPN 之前,MMU 必须访问 k 个 PTE。
访问 k 个 PTE,第一眼看上去昂贵而不切实际。然而,这里 TLB 能够起作用,正是通过将不同层次上页表的 PTE 缓存起来。实际上,带多级页表的地址翻译并不比单级页表慢很多。
五、Linux 虚拟内存系统¶
本章将对 Linux 的虚拟内存系统做一个描述,使你能够大致了解一个实际的操作系统是如何组织虚拟内存,以及如何处理缺页的。
如图所示,Linux 为每个进程维护了一个单独的虚拟地址空间:
- 熟悉的代码、数据、堆、共享库以及栈段。
- 内核虚拟内存,位于用户栈之上。
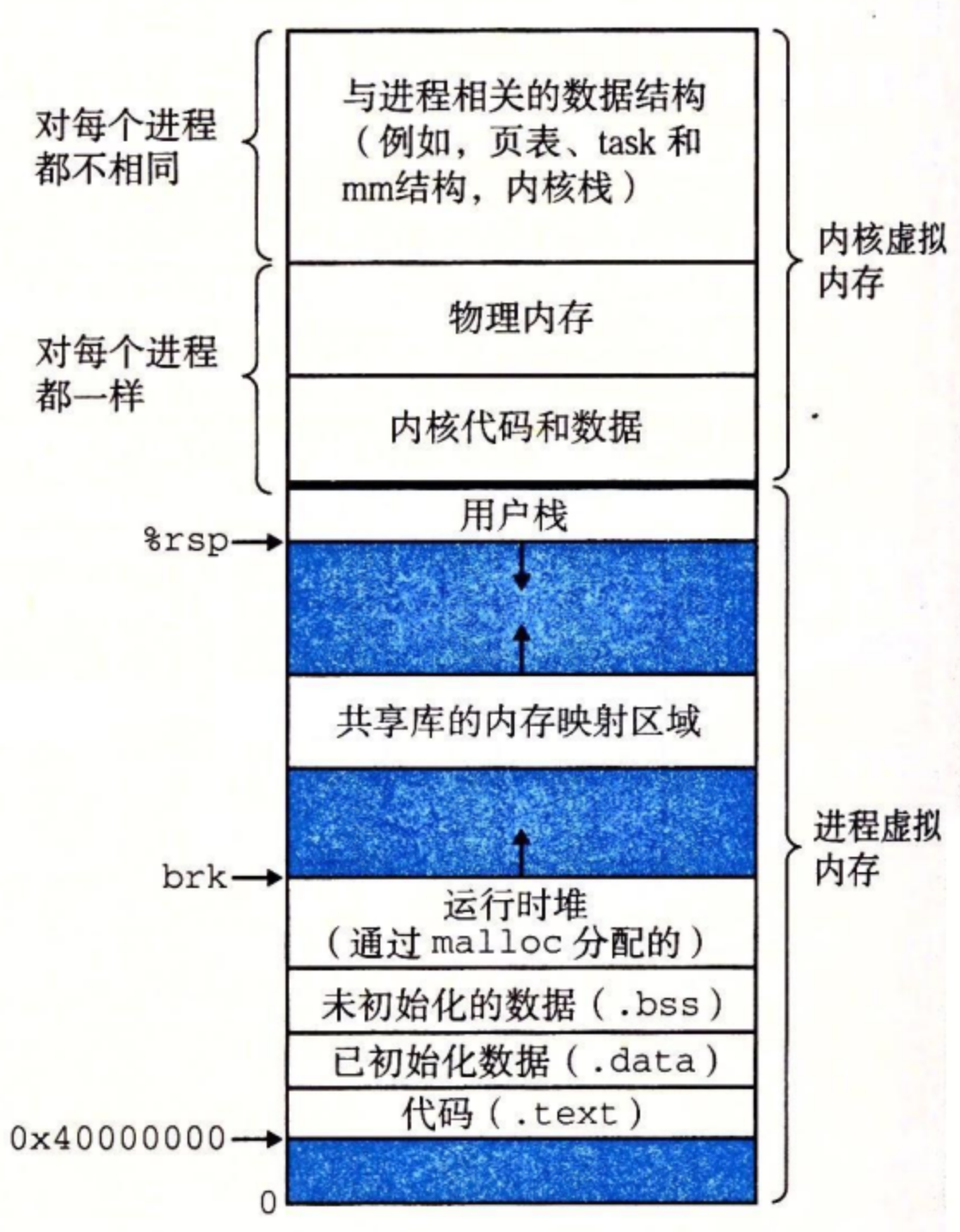
内核虚拟内存包含内核中的代码和数据结构:
-
某些区域被映射到所有进程共享的物理页面。例如,每个进程共享内核的代码和全局数据结构。
-
其他区域包含每个进程都不相同的数据。比如说,页表、内核在进程的上下文中执行代码时使用的栈,以及记录虚拟地址空间当前组织的各种数据结构。
那虚拟内存区域到底指什么?
Linux 将虚拟内存组织成一些区域(也叫做段)的集合。一个区域(area)就是已经存在着的(已分配的)虚拟内存的连续片(chunk),这些页是以某种方式相关联的。例如,代码段、数据段、堆、共享库段,以及用户栈都是不同的区域。
每个存在的虚拟页面都保存在某个区域中,而不属于某个区域的虚拟页是不存在的,并且不能被进程引用。
区域的概念很重要,因为它允许虚拟地址空间有间隙。
内核不用记录那些不存在的虚拟页,而这样的页也不占用内存、磁盘或者内核本身中的任何额外资源。
内核为系统中的每个进程维护一个单独的任务结构(源代码中的 task_struct)。任务结构中的元素包含或者指向内核运行该进程所需要的所有信息(例如,PID、指向用户栈的指针、可执行目标文件的名字,以及程序计数器)。
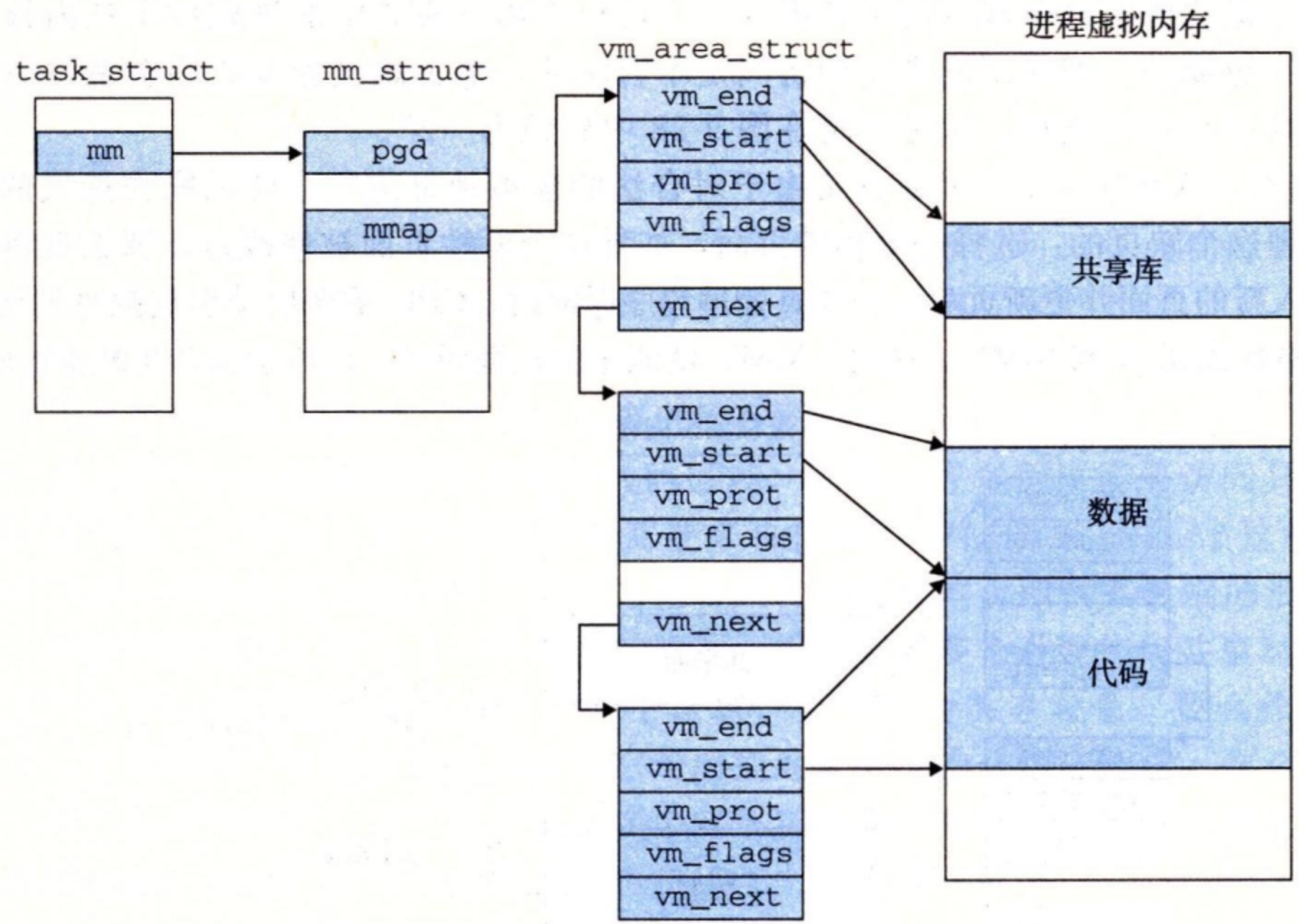
任务结构中的一个条目指向 mm_struct,它描述了虚拟内存的当前状态。我们感兴趣的两个字段是 pgd 和 mmap,其中 pgd 指向第一级页表(页全局目录)的基址,而 mmap 指向一个 vm_area_structs(区域结构)的链表,其中每个 vm_area_structs 都描述了当前虚拟地址空间的一个区域。当内核运行这个进程时,就将 pgd 存放在 CR3 控制寄存器中。
为了我们的目的,一个具体区域的区域结构包含下面的字段:
- vm_start:指向这个区域的起始处。
- vm_end:指向这个区域的结束处。
- vm_prot:描述这个区域内包含的所有页的读写许可权限。
- vm_flags:描述这个区域内的页面是与其他进程共享的,还是这个进程私有的(还描述了其他一些信息)。
- vm_next:指向链表中下—区域结构。
六、内存映射¶
Linux 通过将一个虚拟内存区域与一个磁盘上的 对象(object)关联起来,以初始化这个虚拟内存区域的内容,这个过程称为 内存映射(memory mapping),虚拟内存区域可以映射到两种类型的对象中的一种:
- Linux 文件系统中的普通文件: 一个区域可以映射到一个普通磁盘文件的连续部分 ,例如一个可执行目标文件。文件区(section)被分成页大小的片,每一片包含一个虚拟页面的初始内容。因为按需进行页面调度,所以这些虚拟页面没有实际交换进入物理内存,直到 CPU 第一次引用到页面(即发射一个虚拟地址,落在地址空间这个页面的范围之内)。如果区域比文件区要大,那么就用零来填充这个区域的余下部分。
- 匿名文件: 一个区域也可以映射到一个匿名文件,匿名文件是由内核创建的,包含的全是二进制零。CPU 第一次引用这样一个区域内的虚拟页面时,内核就在物理内存中找到一个合适的牺牲页面,如果该页面被修改过,就将这个页面换出来,用二进制零覆盖牺牲页面并更新页表,将这个页面标记为是驻留在内存中的。注意在磁盘和内存之间并没有实际的数据传送。因为这个原因,映射到匿名文件的区域中的页面有时也叫做请 求二进制零的页(demand-zero page)。
无论在哪种情况中,一旦一个虚拟页面被初始化了,它就在一个由内核维护的专门的 交换文件(swap file)之间换来换去。交换文件也叫做 交换空间(swap space)或者 交换区域(swap area)。需要意识到的很重要的一点是,在任何时刻,交换空间都限制着当前运行着的进程能够分配的虚拟页面的总数。
交换空间就是虚拟内存存储的地方,通常就是在磁盘上的一个文件!
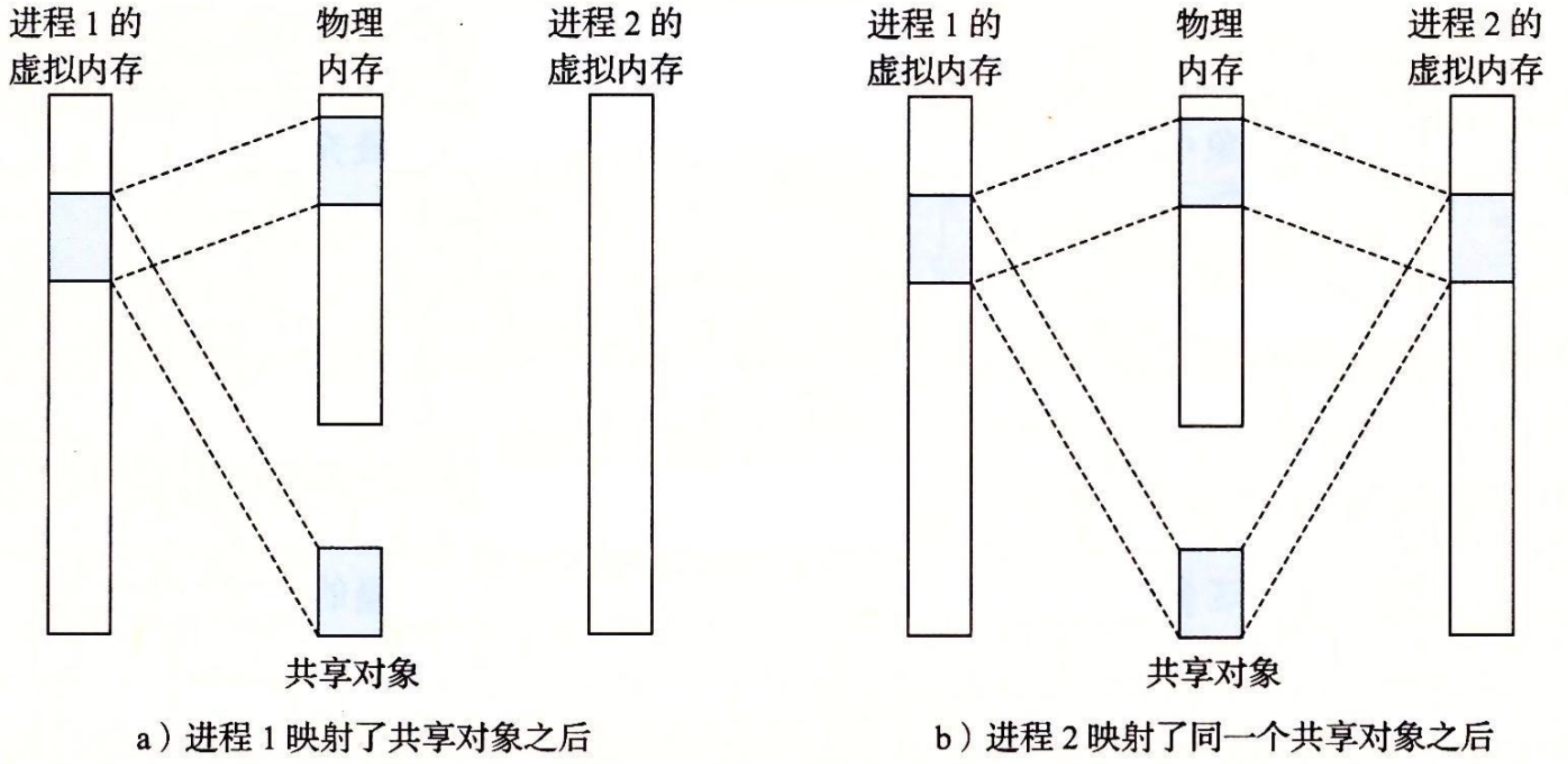
再看共享对象
进程这一抽象能够为每个进程提供自己私有的虚拟地址空间,可以免受其他进程的错误读写。不过,许多进程有相同的只读代码区域,例如,每个 C 程序都需要来自标准 C 库的诸如 printf 这样的函数。
内存映射给我们提供了一种清晰的机制,用来控制多个进程如何共享对象。
一个对象可以被映射到虚拟内存的一个区域,要么作为共享对象,要么作为私有对象。
- 如果一个进程将一个共享对象映射到它的虚拟地址空间的一个区域内,那么这个进程对这个区域的任何写操作,对于那些也把这个共享对象映射到它们虚拟内存的其他进程而言,也是可见的。而且,这些变化也会反映在磁盘上的原始对象中。
- 另一方面,对于一个映射到私有对象的区域做的改变,对于其他进程来说是不可见的,并且进程对这个区域所做的任何写操作都不会反映在磁盘上的对象中。
一个映射到共享对象的虚拟内存区域叫做 共享区域。类似地,也有 私有区域。
如图所示,进程 1 将一个共享对象映射到它的虚拟内存的一个区域中,随后进程 2 将同一个共享对象映射到它的地址空间(并不一定要和进程 1 在相同的虚拟地址处。
因为每个对象都有一个唯一的文件名,内核可以迅速地判定进程 1 已经映射了这个对象,而且可以使进程 2 中的页表条目指向相应的物理页面。
私有对象使用一种叫做 写时复制(copy-on-write)的巧妙技术被映射到虚拟内存中。一个私有对象开始生命周期的方式基本上与共享对象的一样,在物理内存中只保存有私有对象的一份副本。
对于每个映射私有对象的进程,相应私有区域的页表条目都被标记为只读,并且区域结构被标记为私有的写时复制。只要没有进程试图写它自己的私有区域,它们就可以继续共享物理内存中对象的一个单独副本。然而,只要有一个进程试图写私有区域内的某个页面,那么这个写操作就会触发一个保护故障。
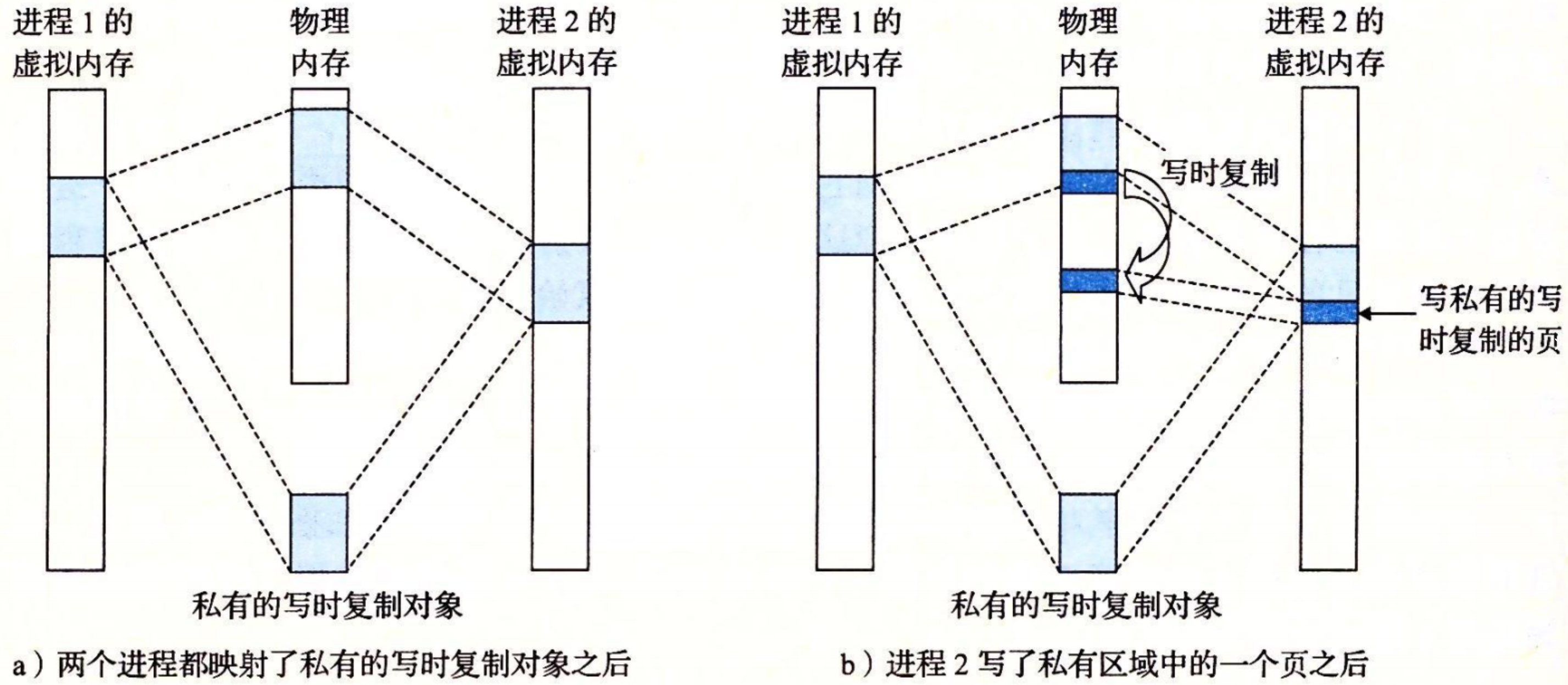
当故障处理程序注意到保护异常是由于进程试图写私有的写时复制区域中的一个页面而引起的,它就会在物理内存中创建这个页面的一个新副本,更新页表条目指向这个新的副本,然后恢复这个页面的可写权限,如图 b 所示。当故障处理程序返回时,CPU 重新执行这个写操作,现在在新创建的页面上这个写操作就可以正常执行了。
通过延迟私有对象中的副本直到最后可能的时刻,写时复制最充分地使用了稀有的物理内存。
再看 fork 函数
既然我们理解了虚拟内存和内存映射,那么我们可以清晰地知道 fork 函数是如何创建一个带有自己独立虚拟地址空间的新进程的。
当 fork 函数被当前进程调用时,内核为新进程创建各种数据结构,并分配给它一个唯一的 PID。为了给这个新进程创建虚拟内存,它创建了当前进程的 mm_struct、区域结构和页表的原样副本。它将两个进程中的每个页面都标记为只读,并将两个进程中的每个区域结构都标记为私有的写时复制。
当 fork 在新进程中返回时,新进程现在的虚拟内存刚好和调用 fork 时存在的虚拟内存相同。当这两个进程中的任一个后来进行写操作时,写时复制机制就会创建新页面,因此,也就为每个进程保持了私有地址空间的抽象概念。
再看 execve 函数
虚拟内存和内存映射在将程序加载到内存的过程中也扮演着关键的角色。既然已经理解了这些概念,我们就能够理解 execve 函数实际上是如何加载和执行程序的。假设运行在当前进程中的程序执行了如下的 execve 调用:
正如之前学到的,execve 函数在当前进程中加载并运行包含在可执行目标文件 a.out 中的程序,用 a.out 程序有效地替代了当前程序。加载并运行 a.out 需要以下几个步骤:
- 删除已存在的用户区域。 删除当前进程虚拟地址的用户部分中的已存在的区域结构。
- 映射私有区域。 为新程序的代码、数据、bss 和栈区域创建新的区域结构。所有这些新的区域都是私有的、写时复制的。代码和数据区域被映射为 a.out 文件中的. text 和. data 区。bss 区域是请求二进制零的,映射到匿名文件,其大小包含在 a.out 中。栈和堆区域也是请求二进制零的,初始长度为零。图 9-31 概括了私有区域的不同映射。
- 映射共享区域。 如果 a.out 程序与共享对象(或目标)链接,比如标准 C 库 libc.so,那么这些对象都是动态链接到这个程序的,然后再映射到用户虚拟地址空间中的共享区域内。
- 设置程序计数器(PC)。 execve 做的最后一件事情就是设置当前进程上下文中的程序计数器,使之指向代码区域的入口点。
下一次调度这个进程时,它将从这个入口点开始执行。Linux 将根据需要换入代码和数据页面。
使用 mmap 函数的用户级内存映射
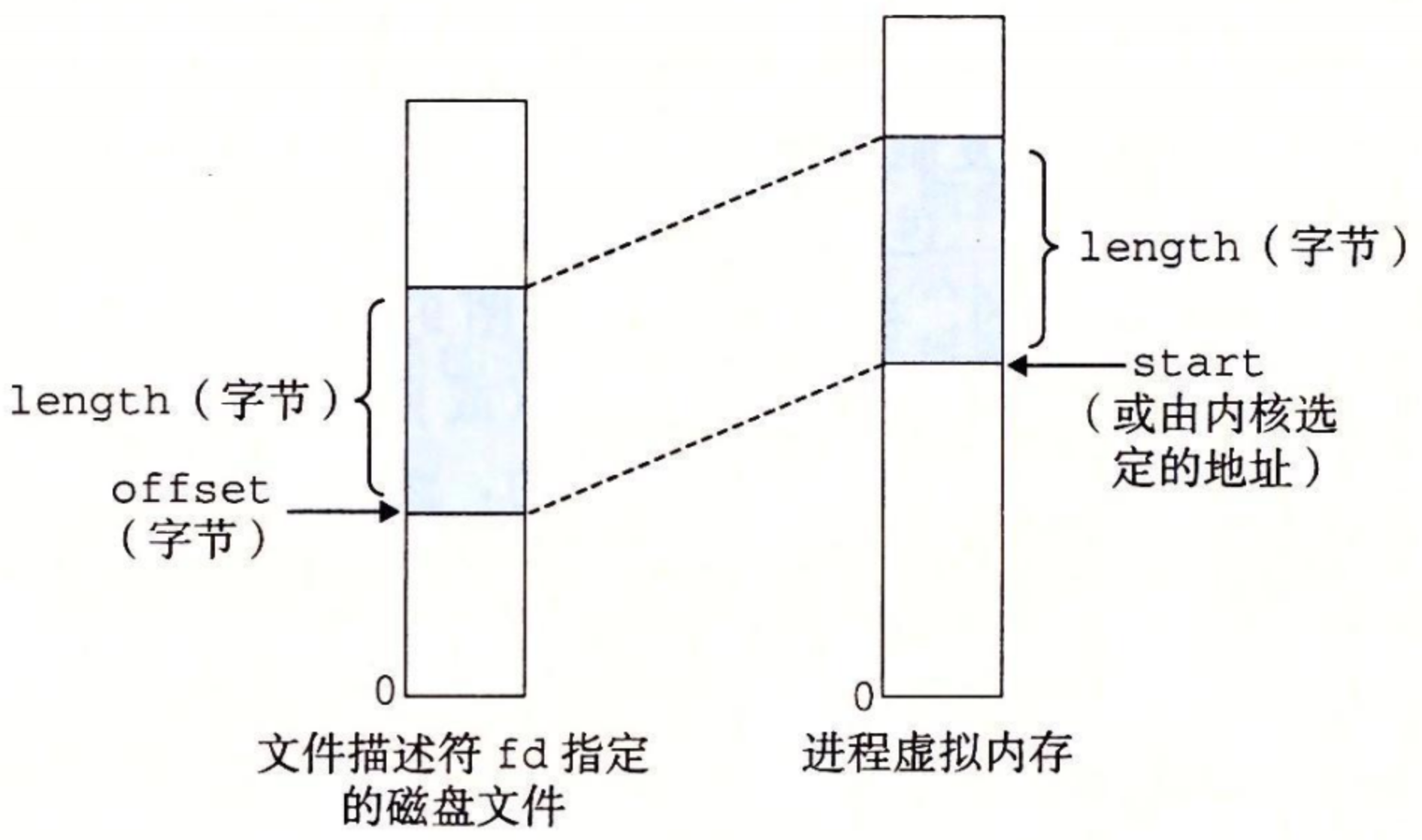
mmap 函数要求内核创建一个新的虚拟内存区域,最好是从地址 start 开始的一个区域,并将文件描述符 fd 指定的对象的一个连续的片(chunk)映射到这个新的区域。
七、动态内存分配¶
就是堆的分配,参考 CSAPP P589
八、垃圾回收¶
IO¶
并发¶
C 程序中常见的与内存有关的错误¶
csapp P609
ASLR 与 PIE¶
csapp p198